I didn’t know about the API resulting from the issue @gareth cited, so I enjoyed exploring it just now. Here’s my findings!
The API was released in CHT 3.11.0, is documented here, and needs a users with _admin role and is called at at /api/v1/users-doc-count.
I have only three users in my local dev instance, all with less than 100 docs. I can call it, pass the results into jq and see the output:
curl -s https://medic:password@192-168-68-108.my.local-ip.co/api/v1/users-doc-count | jq
{
"limit": 10000,
"users": [
{
"_id": "replication-count-abdul",
"_rev": "1-0a35a0e096a985510662dc2fd4417eca",
"user": "abdul",
"date": 1659111882929,
"count": 46
},
{
"_id": "replication-count-mrjones",
"_rev": "1-4de640ce4ef29b812b30b5b8a6c040c7",
"user": "mrjones",
"date": 1659101850205,
"count": 34
},
{
"_id": "replication-count-mrjones-replacement",
"_rev": "1-7a5593328e882f851ddc80e87763bcf8",
"user": "mrjones-replacement",
"date": 1659110993531,
"count": 40
}
]
}
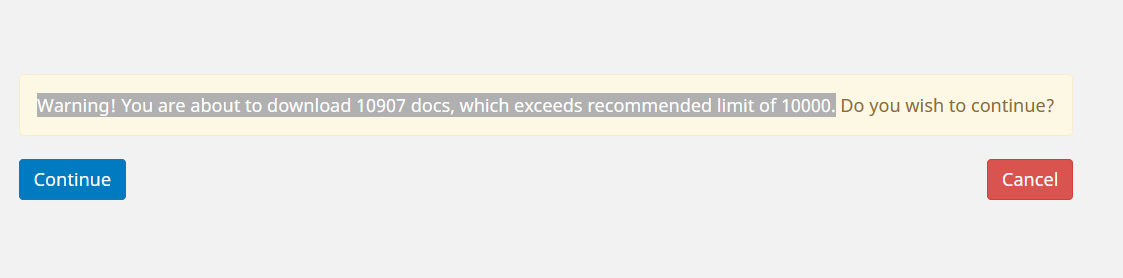
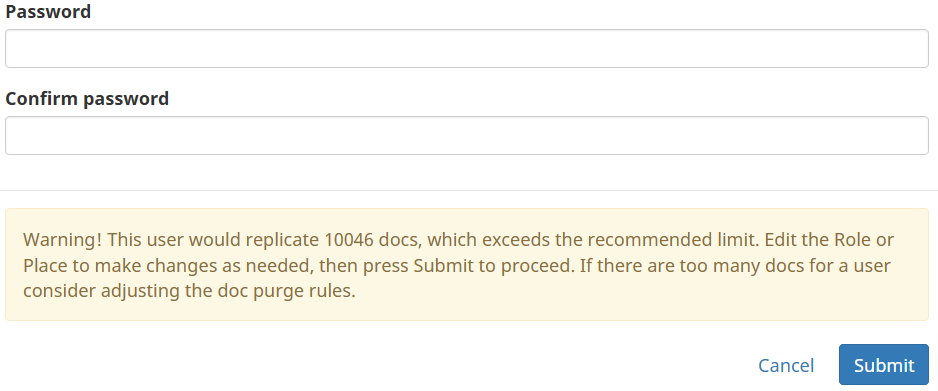
However, what if I have 10s, 100s or even 1000s of users? How can I easily know which users are over the limit of 10000? Thanks to the power of jq, we can easily filter out any users above 10,000 and show just their count and username. For my case, I’ll filter at or above 40 to show the filter working:
curl -s https://medic:password@192-168-68-108.my.local-ip.co/api/v1/users-doc-count | \
jq '.users[] | select(.count >= 40) | .count, .user'
46
"abdul"
40
"mrjones-replacement"
Hopefully this helps anyone else reading this thread - cheers!