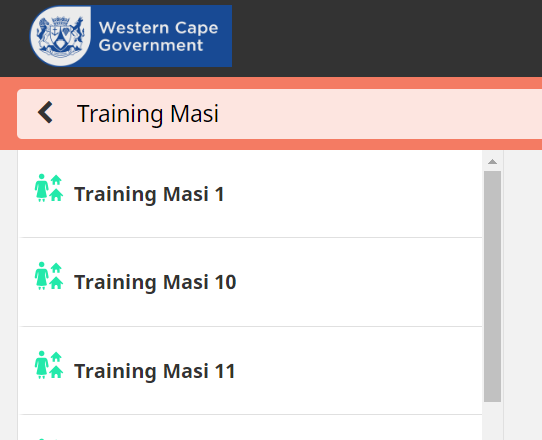
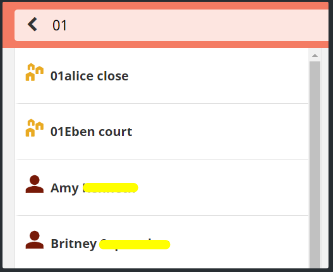
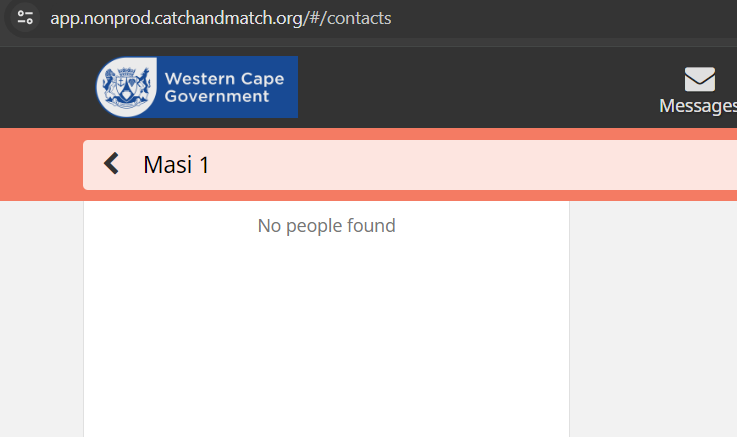
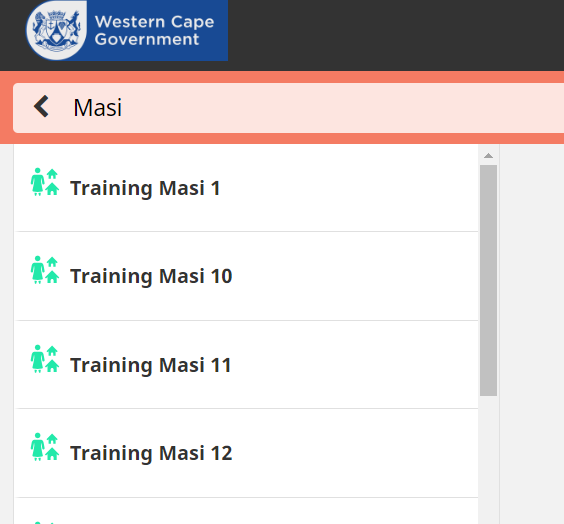
I think I know what’s happening here. When indexing documents, the title and several other fields are split up into key words. For example: “training masi 1” becomes “training”, “masi” and “1”. Then the CHT ignores keywords that are less than 3 letters long, in your case “1” because these would often get too many results.
When you type in a search term it also gets split up into words but I think there’s a bug where the short words aren’t ignored, which means in your case you’re searching for “Masi” AND “1” which gets no results because the “1” isn’t found.
The workaround is to only search using words that are at least 3 letters long.
Does this work for your use case? Will your production facilities be numbered as in the training instance, or will they have longer names?
Thank you for all the provided info, this enabled us to look more critically at how were structuring our hierarchy place names; while also being able to delve deeper into the duplicate data capture issue.
I’m glad to hear the “inconsistent search result” bug has been resolved in the upcoming v4.6 version.
As for now, I’ve conveyed the 3 character workaround. While it will help with some cases, in the rural areas, which arguably requires the most care, there seems to be an established naming process:
So far location “addresses”/descriptions appear to be the main fields affected, specifically in the informal settlements where there are no roads or erfs. Every shack gets a number, and the area gets a letter or set of letters. Those two are then combined. The CHW adds more details in the description field, e.g. “With blue door next to dead tree, one row back.”
Whole suburbs in informal areas have also been described using single letters historically, e.g. Site B or Site C in Khayelitsha.
As outlined above this often leads to places being named “NW 1”, “NW 2”, etc.
It would be impossible to search for these entities, and would be quite laborious to find the correct place.
Implementing some sort of concatenation could be dangerous as a blanket implementation - for instance if we have a place called “15 Ys Street”, which for argument sake is a legitimate address.
We’ve dreamt up an idea of affixing special characters (like ~) to words with less than 3 characters. The search will also need to be tweaked to do the same thing in order to produce a match.
These special characters will then need to be ignoring from display everywhere else.
Seems like quite an undertaking, and essentially it will have the same effect as simply lowering the search count to 2 characters.
Do you know of another way we could approach this? Has anyone else run into such an issue?
The search indexes (almost) every field in every contact so you don’t need to just use name or address. In your example you could search for “blue door” and get a result. Or if you have a unique identifier like a national ID you could search for that either by typing in the number or soon, using barcode search. Unfortunately the search works particularly poorly for addresses where the number is usually too short to index.
I think we need to take another look at freetext search. The existing solution doesn’t perform well and frequently causes misunderstandings or fails to account for use cases such as yours. For example, we index all fields in the contact, but it’s clear most people just search by the name of the person/place so it would be much more efficient to just search the name, perhaps efficient enough that we could search much shorter keywords, potentially even single words
Tagging @michael here in case he has any thoughts about the overall search experience.
That is a good point. Is there a way to include a sort of “subtitle” in the list tile or list entry in order to visually represent the reason why this record got a hit on such a search term?
I assume it will have a screen real-estate impact, but perhaps it’s a relatively small trade off compared to the clarity it provides.
Eg. At the moment searching for “blue door”, in this case, would just a show a list entry with the name “NW 1” - which as you’ve noted is a bit jarring.
What are your thoughts?
I’m excited to hear about the barcode searching capabilities. I believe some of our stakeholders have expressed interest not too long ago.
Thank you for taking the time to further investigate the search functionalities, and the impact thereof.
Perhaps as a interim solution numbers, specifically, could be handled differently compared to normal words?
We’ve had a lot of questions and issues raised where people think search is broken because the term isn’t shown in the list view. While this is working exactly as intended it’s clearly not what people expect. Furthermore indexing all those properties is incredibly expensive (the freetext views are easily the largest views in any CHT instance) so if people are only using it to search the name then it would be more intuitive and far faster to only index the name. So fast in fact that we probably wouldn’t need the 3 letter keyword limit.
I suggest we have a look at the telemetry around searching and see if we can figure out what people are using the freetext search field for and then we can make an educated decision about how it should be optimised for both usability and performance.
Hi @Anro, we’ve found that in most projects, it’s not common for CHWs to interact with the search function. It is very possible that CHWs don’t even know about the search feature or that they try it and have a poor experience (slow, inaccurate / unexpected results, etc…) and don’t try it again, but I also think they find that it’s actually just easier to scroll through a few pages of households than it is to conduct a search. The UX could definitely be improved and we’d love to do some more research around this though so if you’d like to help out with that, please let us know (cc: @Nicole_Orlowski)
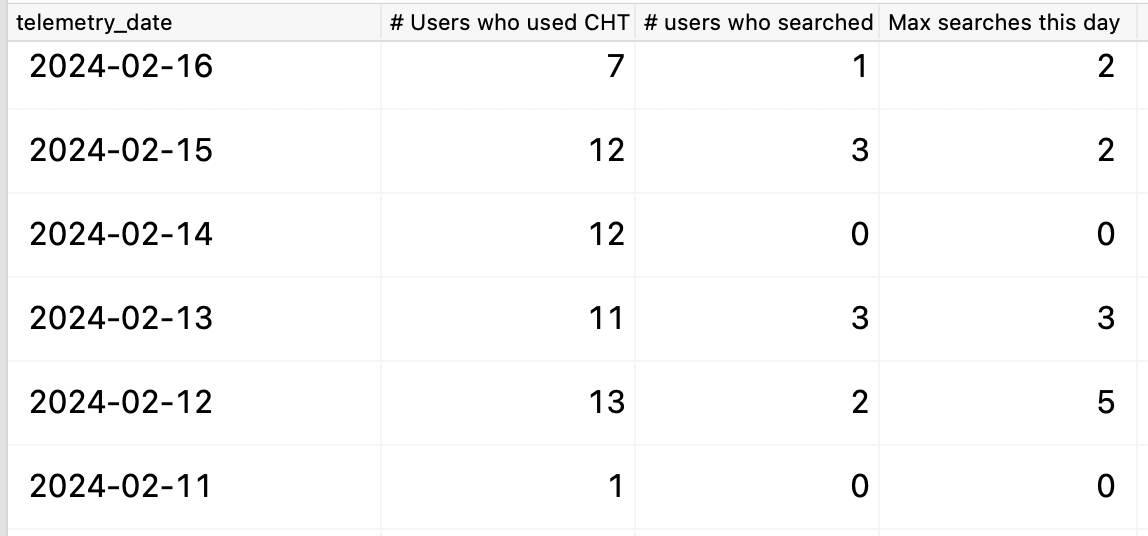
I’ve got a couple of SQL statements you can run to learn more about how often users are interacting with search (on the Contacts page) in your project. Would you be willing to share this output with us?
SELECT
telemetry_date,
count(distinct(meta_user)) AS "# Users who used CHT",
count(distinct(meta_user)) FILTER (WHERE search_contacts_search_count > 0) AS "# users who searched",
max(search_contacts_search_count) AS "Max searches this day"
FROM
(
SELECT
concat_ws(
'-',
doc#>>'{metadata,year}',
doc#>>'{metadata,month}',
doc#>>'{metadata,day}'
)::date as telemetry_date,
doc#>>'{metadata,user}' AS meta_user,
COALESCE((doc#>>'{metrics,search:contacts:search,count}')::int,0) AS search_contacts_search_count
FROM
couchdb_users_meta
WHERE
doc->>'type'='telemetry'
) AS subquery
GROUP BY
telemetry_date
ORDER BY
telemetry_date DESC
SELECT
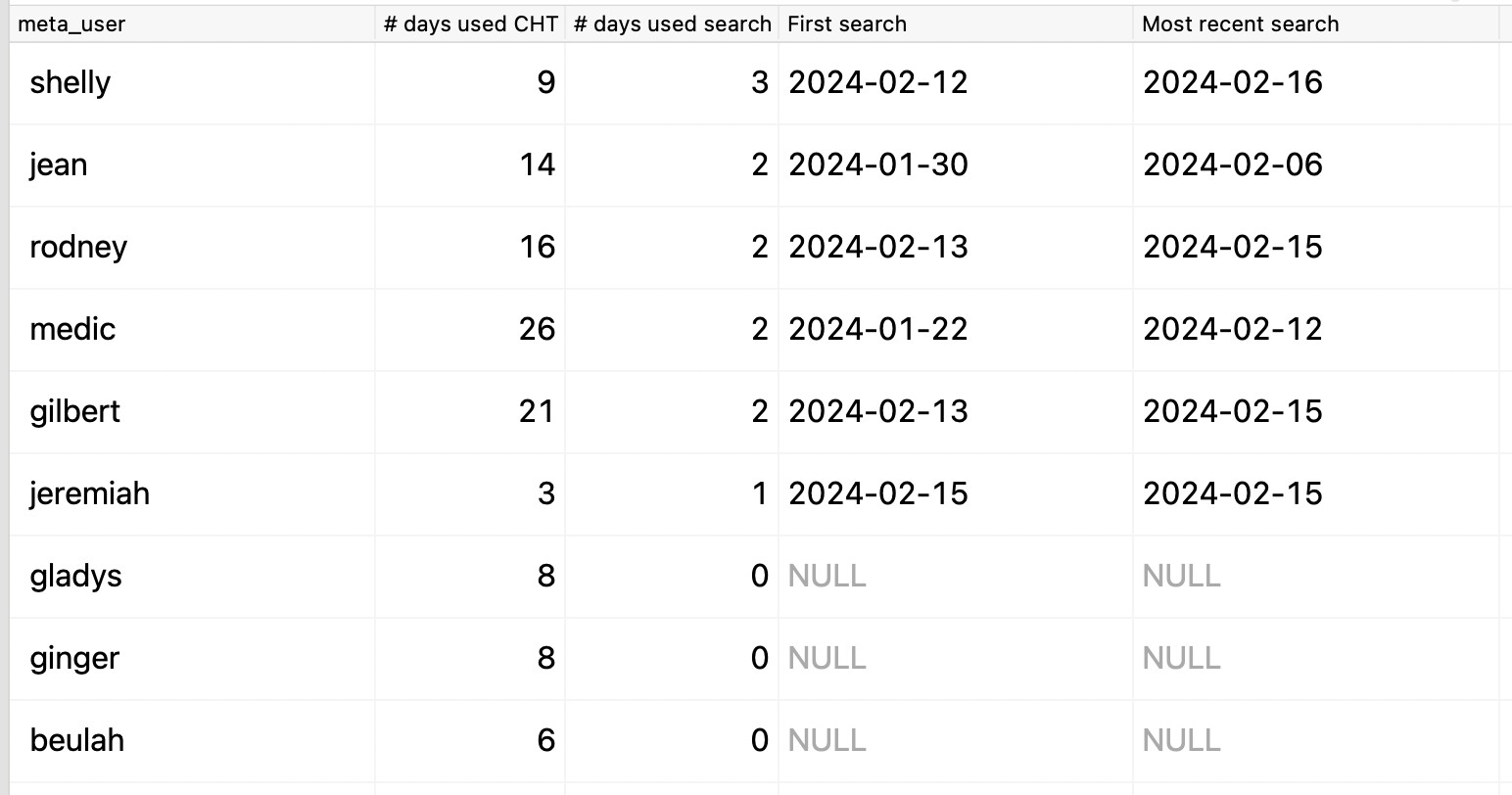
meta_user,
count(distinct(telemetry_date)) AS "# days used CHT",
count(distinct(telemetry_date)) FILTER (WHERE search_contacts_search_count > 0) AS "# days used search",
min(telemetry_date) FILTER (WHERE search_contacts_search_count > 0) AS "First search",
max(telemetry_date) FILTER (WHERE search_contacts_search_count > 0) AS "Most recent search"
FROM
(
SELECT
concat_ws(
'-',
doc#>>'{metadata,year}',
doc#>>'{metadata,month}',
doc#>>'{metadata,day}'
)::date as telemetry_date,
doc#>>'{metadata,user}' AS meta_user,
COALESCE((doc#>>'{metrics,search:contacts:search,count}')::int,0) AS search_contacts_search_count
FROM
couchdb_users_meta
WHERE
doc->>'type'='telemetry'
) AS subquery
GROUP BY
meta_user
ORDER BY
"# days used search" DESC
Hi @michael, unfortunately the results would most likely follow suite this side. We’ve only very recently explicitly asked our CHWs to start using the search feature when we found an increased amount of duplicate data entries being captured.
It could have been due to:
Their lists becoming too large to easily spot existing records
The 50 contact list item limit bug
Them being used to a duplicate check on new contact creation
I unfortunately don’t have access to our prod databases just yet. Our data scientist is looking into pulling the users_meta data through to our community db, however it might take some time. I’ll be sure to relay the anonymized results back to you asap.
I don’t believe there would be much data available from our go-live on November 30th, 2024, until now. As far as I’m aware, the search feature has largely gone unused.
With that said, as per conversations in this thread & the thread linked above, we recently made a test adjustment to the contacts_by_freetext ddoc just last week. We’re now only indexing the name: related values, enabling searches from one character onwards. This change accommodates short names, including single digits, for plots and locations.
Eg:
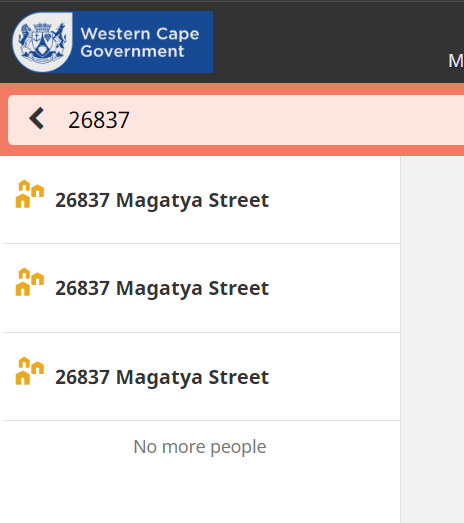
In order for the xform db lookup widget (db-object-widget.js) to follow suite, we’d need to edit the select2-search.service.ts file - updating the minimumInputLength to “1”. And of course edit the contacts_by_type_freetext view in order to index the required values similar to the above-mentioned view.
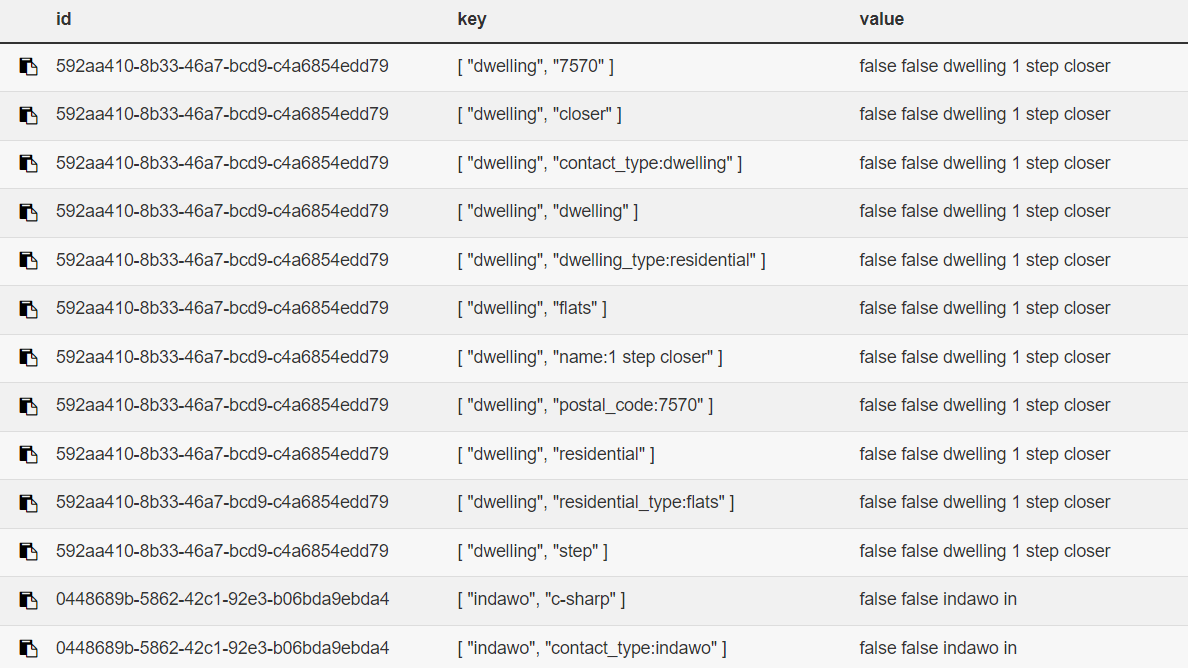
As can be seen, unedited it does not index the “1” in the “1 Step closer” dwelling (and still indexes all the other record info that we’re not interested in searching on):
Just to make sure, as I could perhaps have missed it, this release does not affect the free text indexing.
In other words, words with less that 3 characters will still be ignored. Simply returning all results while adhering to other words that could be part of the search term.
Using “1 step closer” as an example:
Searching the full term will return the item.
Searching “step” will return the item.
Searching “closer” will return the item.
Searching only “1” will NOT just return this item, but rather all items.
Searching “1 Step” will return the item, but only because “step” causes the hit. “1” is ignored.
Am I understanding this correctly?
What are your thoughts on the implementation mentioned above with regards to index tweaking?
@michael I’m still waiting on our data scientist for the query results, apologies for the delays.
The release fixes a bug which improves some outcomes, because before your examples 1 and 5 would not return the item, and 4 would return no items at all. This is definitely not the perfect solution but it is an improvement from 4.5.0.
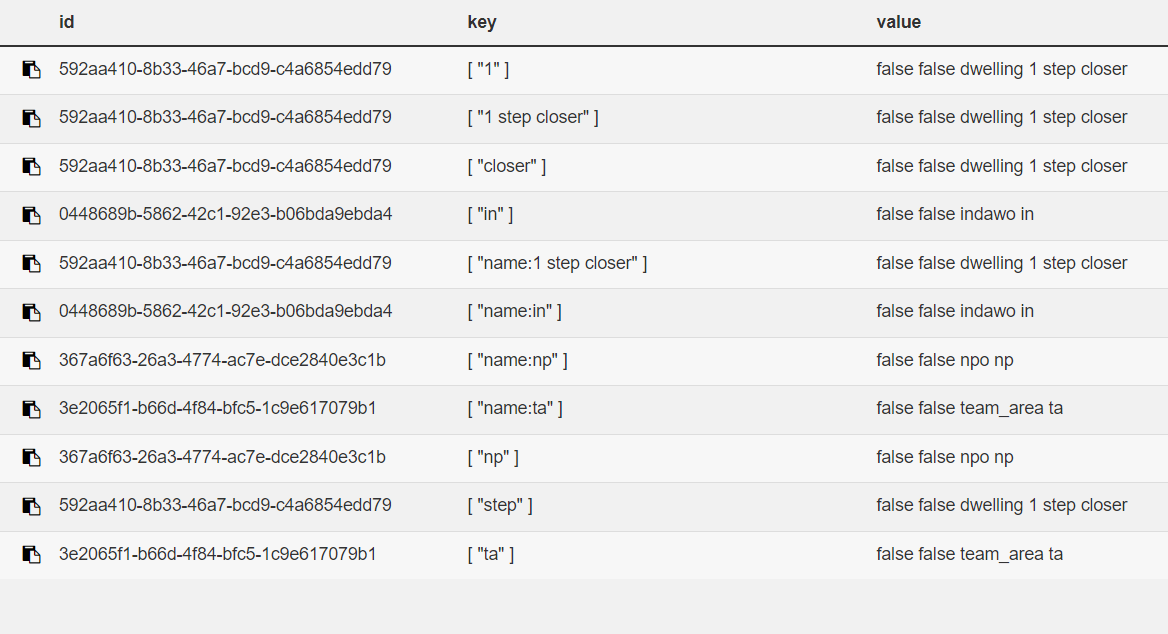
We’ve noticed out of the box, if memory serves, CHT seems to append certain ‘keys’ to search index items.
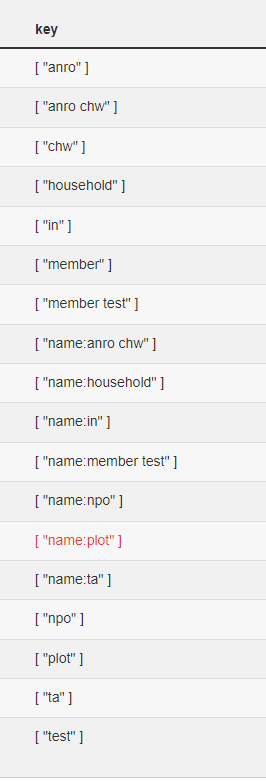
For example the name: key, like above, is present in multiple entries - which causes multiple results being returned if “Na” or “name” is searched.
Is there a reason these keys are included? I just want to make sure there’s no behind the scenes tie-ins that necessitate these values.
Another advanced feature of searching is you can prefix the field name so if you want to search only on the name you can say “name:gar”. If searching for “nam” is matching all records then that’s a bug in the system - it should only kick in if the user types in something with a “:”.
I think it’s also used in one or two places within the CHT where we link to reports by case ID.
Ultimately I suspect that field searches are another unused feature that we should consider removing to improve the performance for queries that are used more frequently.
Not sure if I missed the mention of the advanced search features, as it’s not listed in the docs’ search section.
Took a look at the generate-search-request.js file, specifically this section:
if (word.indexOf(':') !== -1) {
// use exact match
params.key = [ word ];
} else {
// use starts with
params.startkey = [ word ];
params.endkey = [ word + END_OF_ALPHABET ];
}
We’re getting a hit on all the indexes that have the prefixed “name:” key.
The code checks if the entered term contains a “:” before performing an exact match. However, when the search term DOES NOT contain a “:”, the prefix is not excluded, causing the else statement to execute and return all these items as a result.
I’m not familiar with the case ID. Could you perhaps please explain how & where this linking takes place?
If a report has a field name “case_id” then there’s a one click link to search for all reports with the same case_id (source). It’s designed to be used with this transition.
I’ve had a quick look at the links provided, thank you, but it’s not immediately apparent how the report case_id’s affects the contact free search indexing.
Is it perhaps that the contact, or hierarchy item, contains a link to the report via a case_id variable?
Where in the app can I find this one click link in order to test this functionality?
That specific piece of code is used when rendering reports. If you create a report with a case_id field then the field value should be a link which triggers the report search. When you click the link it will search for case_id:123465.
But the link is just a convenience for that specific use case, and we could replace it with something else if we wanted to get rid of the fieldname prefix search feature.
Thanks, @gareth, for the detailed explanation! While we don’t use the reporting section much, and most of our reports are handled off-app, having that link as a convenience for searching by case ID seems quite handy. It’s good to know there’s flexibility in potentially replacing it with something else down the line if needed.
With regards to the registrations, it seems to primarily deal with validation and confirmation messages when items are registered via some contact_create form. Is this specific to SMS-driven entity creation, or does it also fire on in-app entity creations?
assigning the relevant place to the report if a registration with the given case_id exists,
It seems that for the case_id linking to work, the hierarchical place item also needs that property with the matching value.
Regarding the “accepting” of the report, it does not refer to the “mark report as accepted” flow in the UI, but more so with regards to the registrations entry having a check that is satisfied and then sends an accepted SMS. Or am I misunderstanding?