Hi,
We are planning to set up a 3 node CouchDB installation for the latest CHT V 4.x
Also, we are looking into implementing a cold/hot storage system and for that we will need to _purge documents from the medic and medic-sentinel databases.
I am wondering if in a multi-node installation, in order to _purge documents from all 3 nodes, we will need to _delete them before _purge them
thanks @diana for the answer
when using CouchDB’s _purge API to delete, for example, a data_record, since the document disappears from the _changes feed, couch2pg does not delete this document from postgresql, however using _delete, couch2pg receives the document with the flag deleted:true from the _changes feed and deletes it from postgresql.
My question was, if we have a multi-node CouchDB and a document is deleted using the _purge API, if the document is _purged from all 3 nodes or not. Even if I can imagine that yes, I feel more at ease with your confirmation.
I’m looking to the first script that you developed here
is it possible to share with us the code that you used in the testing ? The code would allow me to learn the process
Thank you again
My question was, if we have a multi-node CouchDB and a document is deleted using the _purge API, if the document is _purged from all 3 nodes or not. Even if I can imagine that yes, I feel more at ease with your confirmation.
Even in multi-node, the document will only exist on one node.
You won’t need to change any script when going clustered, behavior for documents should be the same as if you were single-node.
Changing CouchDb configuration differs in clustered, but that’s unrelated to documents.
Thanks again @diana
During the last test, you modified the _purge script to keep the server responsive, as follows, you:
Reduced batch size from 100 to 50
Added 10 retries for each purge batch to stabilize spikes
Called views after each purge request
If the modified script cannot be shared with us, could you please give us the list of views you called after the purge request or should the script call all views in the database?
My conclusion after running purging is that it is so completely disruptive, it needs intentional scheduling, batching and close watching, and my recommendation was to not use it against production instances.
I have no problem sharing the updated script with you, with my recommendation that this is not safe to use due to the extent of destabilization it can cause for an instance.
The script can be found here: GitHub - dianabarsan/simplified_purging . Please note that I have not taken the time to make this production ready and should be considered in alpha mode: nobody has reviewed this code and I haven’t added sufficient test coverage. I discontinued working on this and deprioritized it due to the discouraging results I got during testing.
It might be possible that Couch 3 behaves differently (is faster for example), but this would require another batch of testing against a fresher instance. I would not base a potential future strategy on this optimistic guess.
Hi @diana
We don’t plan to use the provided code with a production instance and I clearly understand your conclusions, however I want to read the code to avoid having to ask basic questions about the process used in the test.
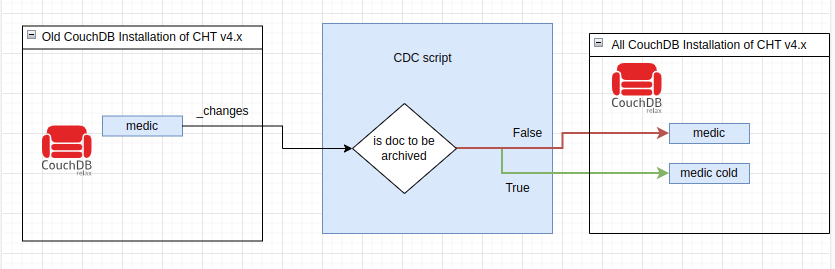
If we can’t do a mass purge in production and we can’t purge offline (on a cloned instance) to transfer the purged database to production, I can only figure out two other options: one, replicate the old database, the one in production now, to the new chtv4 database filtering out the documents we don’t want to purge, something like this
The second, purge daily in production a small amount of documents and observe the server response to increase or decrease the next amount of documents to purge combining with vertical scalation of the server during purging
one, replicate the old database, the one in production now, to the new chtv4 database filtering out the documents we don’t want to purge, something like this
I think this is a very risky and human-resource consuming endeavor.
This would mean that you would need to run this filtered replication, which will take a long time, and then run view indexing over the replicated data, instead of running it on the muso instance while it’s still up.
Someone would need to set up this filtered replication, test it, run it against the prod instance and babysit it, then make sure all data is ok. And then all indexing and migration would need to be done on the new dataset.
Not to mention that this is time constrained.
second, purge daily in production a small amount of documents and observe the server
I think this is easier to achieve, depending on how many docs you intend to purge daily. This was my suggestion to use the purging script, actually. But purging 20 mil documents, the initial list that was delivered, in a span of 3 months (a random number) would require purging 200.000 documents every day, which, from what i saw, was unrealistic. So you’d be looking at a longer interval to get this doc count down.
Thans @diana again
First of all, we would like to express our gratitude for the time and patience you have taken to answer our questions.
We understand that a mass purge is not feasible in production and that the other possible solutions involve too many risks and we agree that they should not be implemented.
A sustained purge of a few documents per day can be tested in production, once the instance in v4, and depending on the server response, can be continued, although it will be a process of several months, 3 to 8 months (200,000 - 65,000 documents per day) to purge the initial 20 million documents.
Once the initial 20 million have been purged and taking into account that 90% of muso’s data_records are home_visit, only purging home_visits older than three months, instead of store all home_visit history, could greatly improve the size of the database and the number of docs per user.
By now, we will concentrate our efforts to get the production instance upgraded to version 4.
We will let you know if we decide to start the “slow daily _purging”