Hi
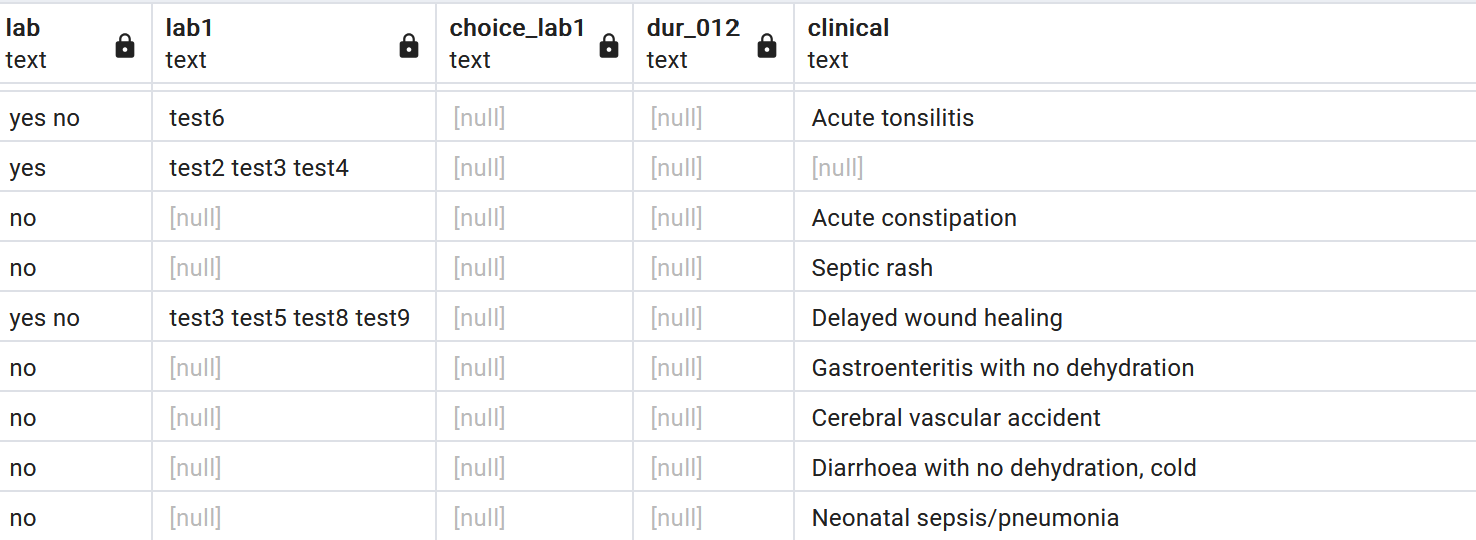
I have a repeat condition for some lab tests, where the clinician selects a number of tests, and for each test indicates the results and diagnosis based on the results as below:
I wish to query the Json data and extract the lab test, result and diagnosis for each repeat test, thus if we do three tests, I expect three lab tests, three results and three diagnosis based on the results. This I will then download in tabular format for analysis using PgAdmin, any ideas on how to write the CouchDB query?
@mrjones, I shared the section with the repeat condition, writing the query as below produces the following results on PostgreSQL:
couchdb.doc #>> ‘{fields,lab}’::text AS lab,
couchdb.doc #>> ‘{fields,lab1}’::text AS lab1,
couchdb.doc #>> ‘{fields,choice_lab1}’::text AS choice_lab1,
couchdb.doc #>> ‘{fields,dur_012}’::text AS dur_012,
couchdb.doc #>> ‘{fields,clinical}’::text AS clinical
@oyierphil data from repeats are stored as an array on the data_record. To work with arrays, you can use the jsonb_array_elements()function. This will give you one row for every item in the array.
A common design pattern would be to have all your non-repeat fields in one table/view, and have a separate view for your repeat section that has different columns for all the fields in the repeat.
So in your example, you might have one view for the report itself, then a second view for the repeat section, and that second view would have three columns… a uuid column that links back to the report view, and columns for choice_lab1 and dur_012
It’s been a while since I’ve worked with these, but to get you started, try selecting something like…
SELECT
doc->>'_id' AS uuid,
jsonb_array_elements(doc#>'{fields,repeat2}')->'choice_lab1' AS lab,
jsonb_array_elements(doc#>'{fields,repeat2}')->'dur_012' AS dur
FROM
couchdb
WHERE
doc->>'_id' = '<example_doc_id>'
@michael, thank you. I went through the documentation of jsonb_array_elements() and ran the query, which worked with minor changes, we now have all the repeat lab tests.
I picked some UUIDs and checked with Fauxton, we are now good.
@michael, @mrjones, I noted after creating materialized views with indexes, from where we created a view joining data from the clinicians and CIF, the downloaded data in CSV format didn’t include all submitted cases from the CHT App.
I did a manual refresh of the views, and even created a function and trigger to refresh the materialized views, the size of the data downloaded is the same, any ideas how to ensure better sync between CoachDB and PostgGres?
I went through the documentation of jsonb_array_elements()… we are now good.
Yay! I’m glad Michael’s tip was able to unbock you.
I did a manual refresh of the views, and even created a function and trigger to refresh the materialized views
I think you’re asking about keeping materialized fresh so that they’re up to date? if yes, I recommend checking out CHT Sync, which includes both an updated version of couch2pg, but also includes automation via CHT Pipeline (via dbt) to refresh materialized views.
This is a very up to date offering which we’re excited for partners to try. Please let us know if you need any help setting this up or have questions.
downloaded data in CSV format didn’t include all submitted cases from the CHT App
Or… maybe you’re suggesting that not all the data is being copied from CouchDB to Postgres?
Refreshing materialized views doesn’t bring any new data from CouchDB to PostgreSQL, it only refreshes those materialized views based on whatever data was already in PostgreSQL.
Also worth mentioning… if you have materialized views that query other materialized views, the order in which you refresh them is important.
@michael, so we have two materialized views and one view, which picks fields from the two materialized views using an inner join.
What would be the best strategy of ensuring that we sync data from CouchDB to PostGres as it comes?
@oyierphil … great, if you have a view that is querying two materialized views, then it should be fine.
couch2pg has a configurable refresh rate, which is an environment variable calledCOUCH2PG_SLEEP_MINS and defaults to 60 minutes. This means that it will wake up every 60 minutes to refresh data from CouchDB to PostgreSQL. But then it takes time for your materialized views to refresh as well.
If you want close to real-time data sync from Couch to PostgreSQL, I would encourage you to look into CHT-Sync as @mrjones mentioned above.
We recently got CHT Sync to a production ready state and we are working on documentation which should be ready in the next 2 weeks or so, I will ping you when it is ready. Meanwhile, please explore the resources shared by @mrjones.
@michael, I have run the query after at the end of each day, and got the same data size, with recent cases from the CHT App missing in PostgreSQL, indicating Couch2pg doesn’t refresh as it should be
Exploring the reason why. Some sites are done data collection and we are under pressure to download all the data and analyze by our project team
@mrjones, yes, not all the data is being copied from CouchDB to Postgres, even after refreshing and running the views, will explore CHT Sync and revert
@oyierphil - CHT Sync’s local setup is pretty easy to test! I just got it working with a local docker helper instance yesterday and published a brief how-to.
@oyierphil are you able to identify what docs are missing from PostgreSQL? Just be sure you are checking for them in the couchdb table in PostgreSQL, that will eliminate the chance that your query definitions for your views aren’t causing the problem.
Yesterday we had a troubleshooting session with Philip and the issue is that couch2pg just runs once, importing a batch of 1k documents and doesn’t run again since the process is terminated after exiting the terminal.
Couch2pg needs to run continuously to process documents in batches configured.
@Philip_Mwago, thank you, great meeting the Medic team at the OpenMRS 2024, @irene, @andra, will review and proceed to configure CHT sync to get real-time syncing.
Using Couch2pg gives data to end of August, but miss data for September.
@oyierphil as CHT Sync documentation and tool are still fresh, I wanted to ask you if you managed to successfully get access to the data you needed for the purpose of analysis? Any feedback you can have can help make the documentation better and clearer. Thank you!