There are ongoing talks on scaling state wide in multiple states. With the current resources we have deployed, It doesn’t look cost effective to scale.
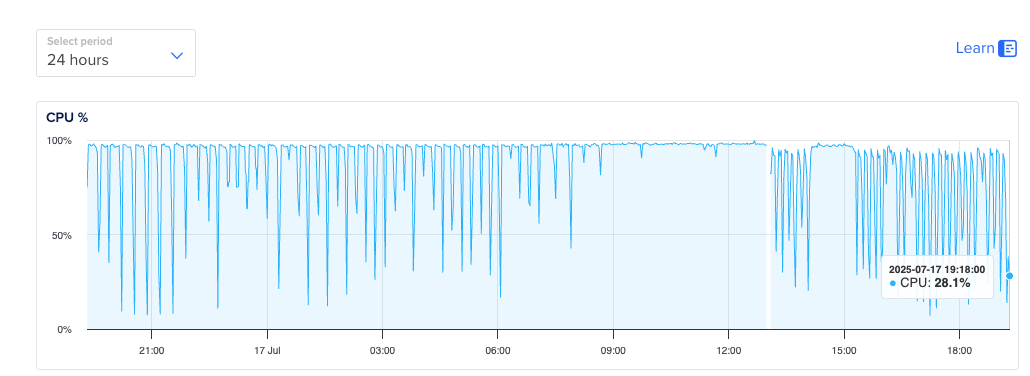
Is there more information you’re able to share? Looking at DigitalOcean pricing, going from 2CPU/4GB → 4CPU/8GB cost ~2x in monthly fees. For this, your CPU went from 100% utilized to ~20% utilized, which represents a 5x increase in capacity.
Given all this, can you share more about why the price to add more RAM and CPU doesn’t look cost effective to scale?
While we’re on the topic of scaling, note that we’ve found CHT prefers a closer mapping of 1 shard : 1 CPU. As we ship with 12 shards by default, all deployments will continue to see dramatic improvements up to 12 CPUs. Likely even going past 12 will help to accommodate for non-couch related tasks.
To be clear though: your deployment has ~20% utilization so does not seem to need more than 4 CPU, even though it is on the low side as Diana said.
One final thought on the server performance is that CHT 4.21 has Couch 3.5 which has been shown to have dramatic improvements, especially as deployments get larger. We recommend upgrading to take advantage of these improvements.
The most affected users at the Local Government HF level will have between 10,000 - 15,000 records loaded on their local DB. Replications take a few minutes to half an hour. This is a big problem when they have clients waiting.
Please note we don’t recommend users have more the 10k documents per user - we’ve found performance can be negatively affected on both client and server.
Can you confirm if the clients have good connectivity when they take 30 minutes to sync? Do they have modern specs in terms of RAM and CPU?
A good way to test this would be:
- find as many offline users as you know of that experience slow sync
- find the fastest laptop with the best WiFi/Ethernet you have access to
- time how long it takes to log in with these affected offline users on the laptop
If the login is very fast, you know the slow sync is caused by connectivity or possibly CPU/RAM on the mobile handsets. If the laptop is slow like the handsets, it is very likely the server.
Some additional resources which might help here are: