Hi team,
The instance is not working yet the payment is okay, the storage , nginx . It was working before but cant seem to find the issue. Requesting for help about what could be the reason.
More information will be very helpful in troubleshooting! First of all, just some basic questions about your deployment:
- Is there production data on the instance?
- How did you deploy it? (docker-compose, etc) Which documentation page were you referencing for the deployment?
- What type of host are you running it on? (Local computer, private data-center, AWS EC2 instance, etc)
- What version of the CHT do you have deployed?
Next, it would help to know a bit more about what problem you are experiencing.
- Is the problem with the clients? (e.g. syncing issues, Android app functionality) or is it an issue with the server?
- Is the application simply not available when you visit the URL? If so, what HTTP error code are you getting (e.g.
404,501, etc) - Can you tell if the server containers are running? (For a docker compose setup, you can check the status of all your containers by running
docker ps -a.)
Probably the host helpful way to diagnose issues with the server will be by looking at the server logs for errors or other indications of an issue.
Hi @Edwin !
It was working before but cant seem to find the issue.
Along with answering @jkuester’s questions, it would be good to know if it was working before, and now it’s not, what changed? Maybe a new app config was pushed with cht-conf or a CHT Core upgradge?
1 Like
@jkuester Sorry for the late reply.
- Yes there is production data on the instance.
- docker-compose
- EC2 instance
- v3.17
- Yes there is the syncing issue started when the instance went down.
- the Public IPv4 Address and DNS does not load the application.
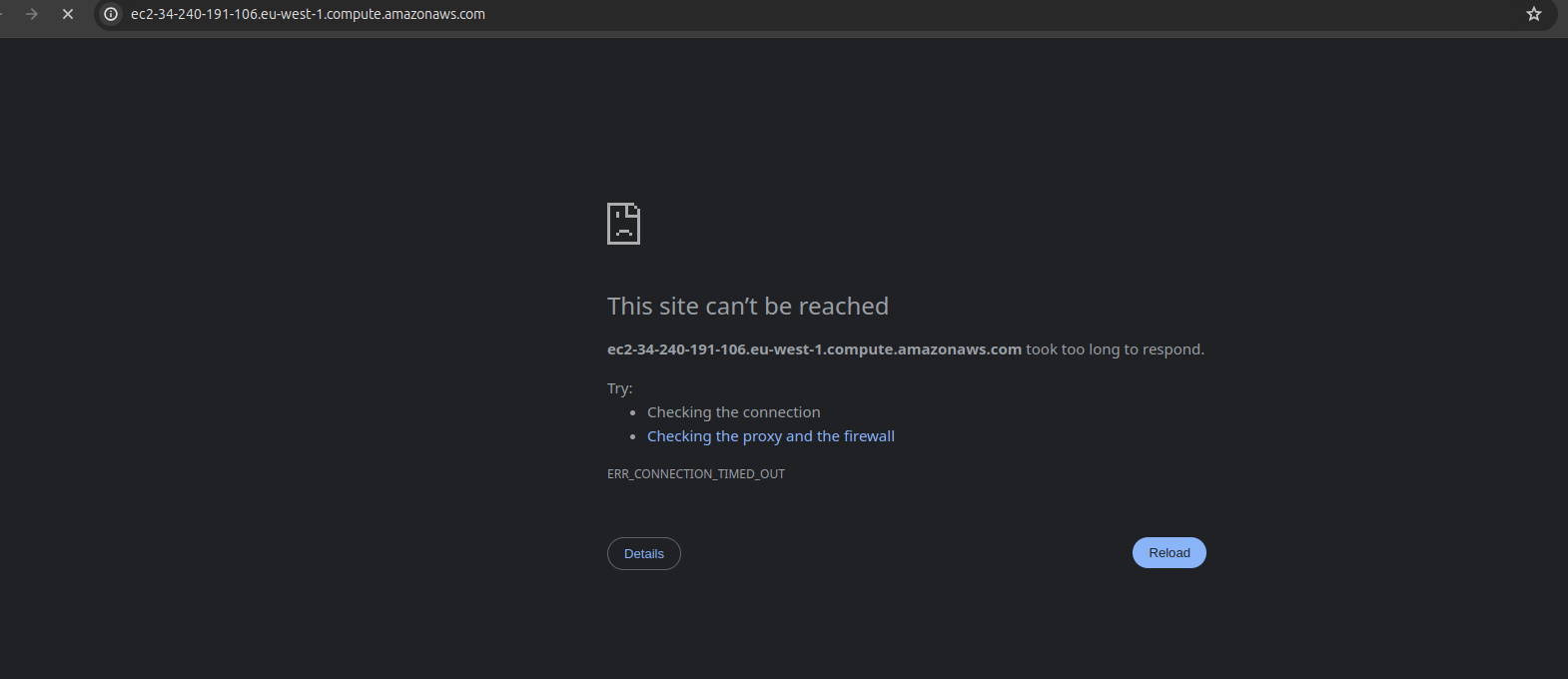
7.The containers are running properly . Would you need a screenshot for this please.
8. @mrjones Yes it was working before. And now it is not . There was no change made. The instance just stopped working. Did reboot it but still the same issue.
It would still be a good idea to check the server logs for any errors. Particularly, it would be good to confirm that there is nothing troublesome in the medic-api logs and that the server seems to be running normally.
That being said, the ERR_CONNECTION_TIMED_OUT error makes me think that something else might be going on here at a level above your actual CHT instance. Something with your DNS/proxy/firewall/etc. Are you running behind any kind of reverse proxy on your EC2 instance?
@mrjones can you double-check me on this? ERR_CONNECTION_TIMED_OUT is now what I would expect to see if the server crashed. What else might cause that?
@jkuester and @mrjones the port had changed. Every time the nginx is started the port was changing. That was causing the error. It was resolved now the instance is back on and also syncing well. Thanks for the help.
1 Like
@Edwin - great to hear you got it resolved! Thanks for sharing that you’re up and running.
Can you explain the fix you made to stop the port from changing? It might help others who encounter this problem.
@mrjones
We encountered accessibility issues with our AWS-hosted instance, specifically through HTTPS, which led us to investigate potential causes. Initial attempts to connect using curl -Iv https://unhcr-app.guilddigital.co resulted in timeouts, suggesting a blockage on port 443, crucial for SSL/TLS connections. An examination of the existing iptables configuration using sudo iptables -L -n -v revealed a default DROP policy on the INPUT chain, notably lacking an explicit allowance for traffic on port 443.
To address this, we modified the iptables rules, incorporating sudo iptables -A INPUT -p tcp --dport 443 -j ACCEPT to explicitly permit incoming traffic on port 443, thereby facilitating secure HTTPS connections. This adjustment was immediately verified through another curl -Iv https://unhcr-app.guilddigital.co attempt, which successfully established a connection, evidenced by a proper SSL handshake and the server’s 200 OK response, confirming that the server was now appropriately configured to accept and respond to HTTPS traffic.
Ensuring the durability of this configuration across system reboots was paramount, so we secured our changes using sudo netfilter-persistent save. This systematic approach not only resolved the accessibility issue but also highlighted the criticality of precise network configuration and management in upholding service accessibility and security standards.
2 Likes
@Edwin - aha! Yes, that makes a lot of sense. Thanks for taking the time to give us the detailed response - very helpful!
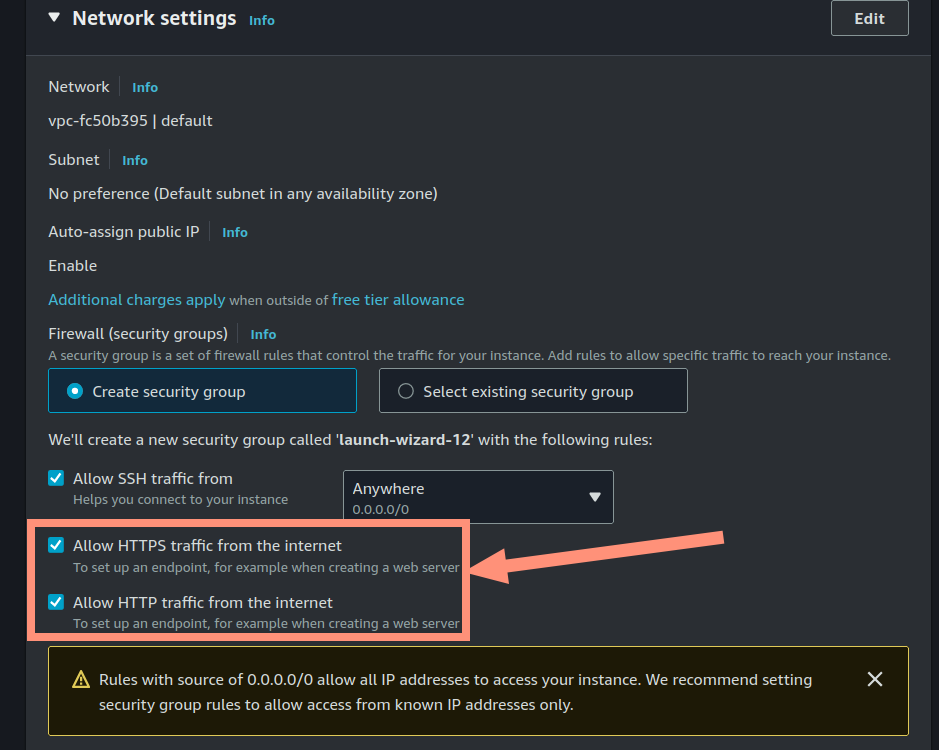
When deploying a new EC2 instance - on the “Network settings” - you can preemptively choose to open HTTP and HTTPS ports, in addition to the default SSH.
Here’s a screenshot for you for next time! See arrow and highlighted rectangle:
2 Likes