Background
The CHT Rules Engine stores a cache of task documents for each contact. Tasks and targets are loaded from cache and only recalculated for contacts with new data.
The cache expires every seven days and tasks for all contacts are recomputed.
This analysis looks at the performance implications of this task cache expiration. It is motivated by challenges experienced by LG-UG with heavy users where the tasks tab is failing to load and sometimes taking ~6 hours to load.
Summary
- The worst-case load times for the Tasks and Targets tabs align with observable cache expiration in CHT telemetry data.
- Heavy CHT users experience slow load times for tasks and targets tab (>15 minutes) which roughly coincide with the task expiration interval. Spikes frequently exceed multiple hours.
- I’m proposing the odds are fair but certainly not guaranteed that task cache expiry is causing or correlated with higher rates of the PouchDB global database failure experienced by LG’s users.
- Three recommendations follow
Correlating Cache Expiration with Performance Degradation
This analysis looks at production telemetry data for a user with frequent app use. The user had 80 telemetry documents within a 90 day window. The user has ~210 contacts on their device so this is not a heavy user. Slowest performance to load tasks tab in this 90 day window was ~57 minutes.
Observing Timing of Cache Expiration
In this figure you can see the real-world timing resulting from CHT Core’s weekly cache expiration. This is calculated as the postgres MAX() of the telemetry system’s MAX of the rules-engine:tasks:dirty-contacts event GROUPED BY day. It is a bit noisy but this generally looks as we might expect.
- Delayed - Cache expirations in mid-Dec and early-January are more than 7 days apart. This can be explained by the user not loading the tasks tab in that period.
- Accelerated - Two refreshes within 7 days on start-Feb could be explained by a code deployment.
- Rolling - In late January the spikes are smaller and the expirations are staggered. This could be because a high number of contacts have their data changed the week prior (server or client-side).
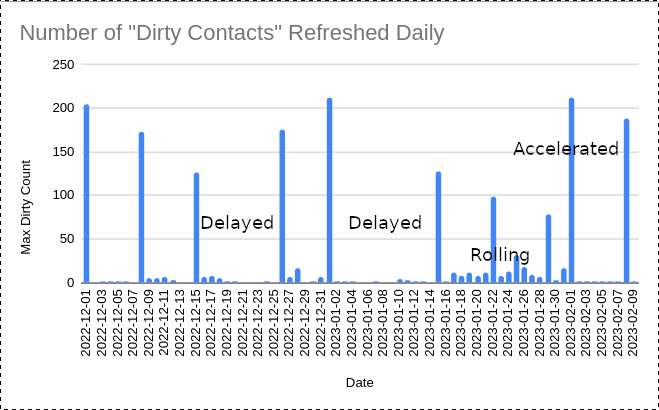
Correlating Cache Expiration with Performance Degradation
This is the load-time of the tasks and targets tabs for the same user. This is calculated as the postgres MAX() of the telemetry system’s MAX of the rules-engine:targets or rules-engine:tasks:all-contacts events GROUPED BY day.
- Spikes on Jan 1, Feb 1, and Feb 8 align well with cache expiration events above.
- Spike on Jan 18 may be due to cache expiration on Jan 15 and user closed the app before completion.
- If the cache expiration is causing performance spikes every time then some expected spikes are missing. This may be explained by
ensureTaskFreshnessbackground thread successfully updating tasks in the background (not measured)rules-engine:tasks-breakdown:all-contactsevents
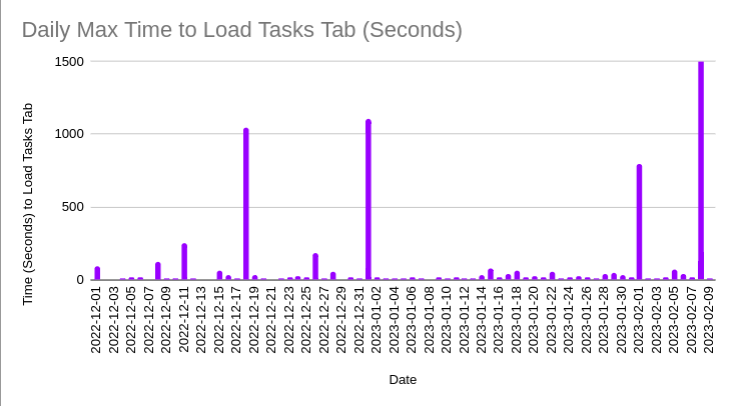
Severity of Degradation for Heavy Users
These figures show the same trend in worst-case task tab load times but now for heavy users. To highlight the weekly frequency for this highly variant data, the vertical axis is fixed at 15 minutes.
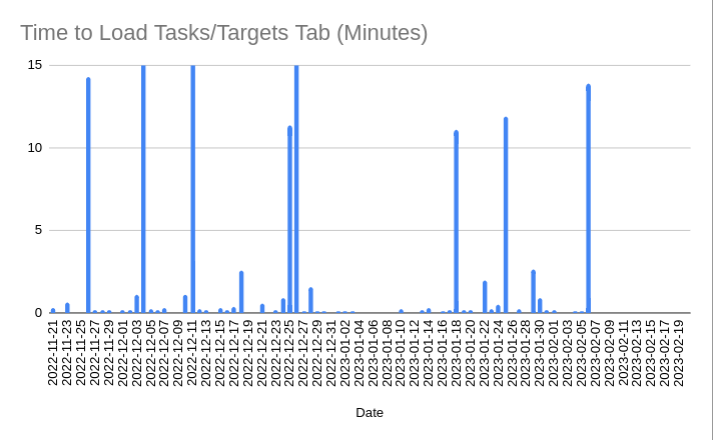
The worst-case load time for this user is ~2 hours (not seen because vertical axis is fixed at 15 minutes).
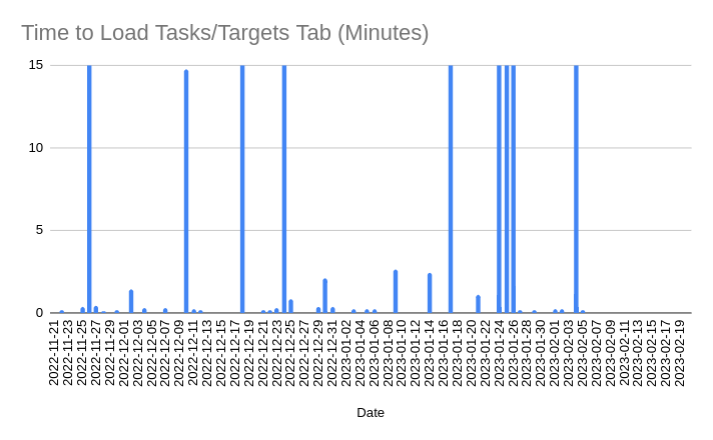
The worst-case load time for this user is ~13 hours.
Synthesis
Why do we expire the cache?
Some tasks or targets rely on the current datetime in their calculation. I believe the most common scenario for this is recurring tasks, logic based on a contact’s current age, and targets can filter emissions based on the current time.
Is this causing LG’s Failure to Load Tasks?
Not directly. Databases shouldn’t globally fail when you use them and the “real” solution for this is below the CHT layer.
But it may be related. Reasons to suspect this is contributing to LG’s Failure to Load Tasks:
- Although the details around timing don’t match well - the general pattern that “tasks are working fine and then they aren’t” is consistent.
- It is reasonable to guess that “doing a lot of PouchDB stuff” is maybe correlated with the mysterious PouchDB global failures. A lot of this PouchDB stuff is happening in the background while the user does other activities which may increase the likelihood of failures.
- Telemetry data for users experiencing the PouchDB global failure have a high number of dirty contacts (1727) and very high load times for the tasks tab (5.7 hours).
I’m proposing the odds are fair but certainly not guaranteed that task cache expiry is causing or correlated with higher rates of the PouchDB global database failure.
How is the expired cache refreshed?
We use multiple PouchDB queries [1 and 2] with a set of keys. Using PouchDB with a large set of keys is very slow. For scenarios like this we would be passing in 1727 keys to PouchDB.
It is highly likely there are more efficient ways to refresh the cache for heavy users.
Recommendations
- Let’s look at more efficient methods to refresh an expired task cache.
- Let’s review the task expiration frequency (currently 7 days). We can look at known configurations and identify other options for the expiration frequency. It may be possible that no expiration is required for some apps.
- We should do an evaluation of tasks and targets requiring cache expiration to function. It’s possible that through better support for these scenarios we could increase the expiration period or remove the need for it completely without adverse effect on projects.