Hi,
This is a part of the cht-datasource DMP project I am working on Parent Issue.
We did have some discussion about this during last week’s Dev hour.
I’ve written a few points stating the advantages/disadvantages of using PATCH and PUT:
Feel free to add comments on this.
Some thoughts:
I think it is inevitable to fetch the Doc on the server before making any sort of updates on it, regardless of any method we choose.
This is because of a case @sugat mentioned during our weekly sync meeting today:
Letting the user update the lineage (parent) for a Doc without verifying if the lineage is accurate could be risky.
Since the get APIs return the lineage unlike the create APIs that just expect the parent id. So, in case of PUT exposed for updating, the user would probably do a GET for the document they wish to update, followed by PUT on something like api/v1/person/:id.
There are some options I can think of:
Only allow parent to be a string containing its uuid, similar to the convention followed in create APIs.
Do not let the user update parent after creation, not sure how valid this option is.
Validate the entire lineage, which might require recursively querying the database to ensure the parent’s parent does exist and other checks.
For some other immutable fields like reported_date, _id we can simply ignore those in case they are part of the payload.
Would love to hear folks’ opinions on this.
I am personally leaning a bit more towards using PUT because it seems to be simpler to implement (at least for now!) and use. Also because we would not have to define conventions for deleting fields from a Doc.
Tagging @jkuester, @diana, @sugat as we discussed some of these points during the previous dev hour.
Thanks so much for being thoughtful and thorough about this!
The fact that there are open questions and risks with using PATCH could be sufficient reason to choose not to implement it in a first iteration.
The lineage change is indeed concerning, modifying a person’s lineage just-so can have high consequences for user replication, and we have an entire algorithm to move people in cht-conf.
I believe that we should only implement the PUT in this initial iteration. It’s simple, straightforward and it’s the way that CouchDb does updates (in my mind, the CouchDb folks also went through these discussions at some point and just decided … nope, no PATCH! just PUT!)
We can circle back to PATCH in a second iteration if the community requests it.
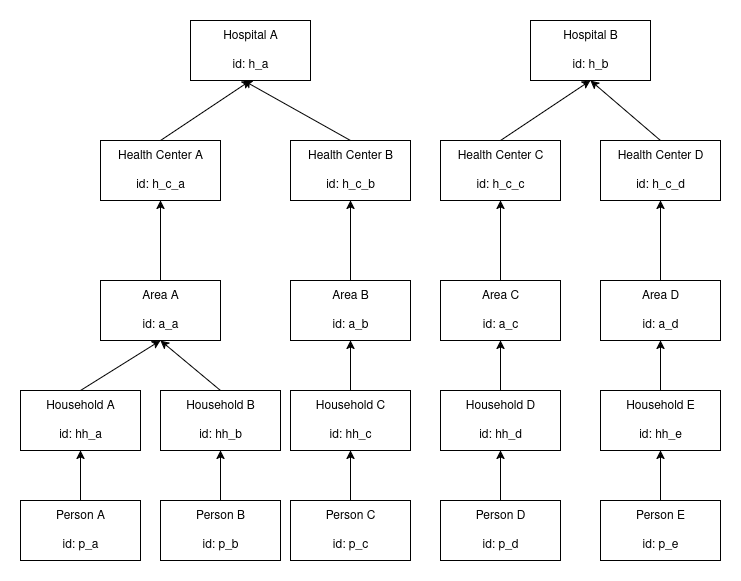
Moving contacts looks fairly complex.
So just wanted to confirm how we should handle parent updates on a contact, if we want to allow them at all.
Do any of the three options in the original message look valid?
One idea that I have is to not allow parent updates in the normal PUT, and instead throw an error saying that the operation has been prevented (and the reason), but we could have a query parameter that would allow updating the parent (an i-know-what-i-m-doing sort of thing).
CouchDb also has this on _bulk_docs where it allows conflicted writes when the new_edits parameter is false.
For the PUT updates, this is the flow I have in my mind:
Get the original doc using the uuid from the path param.
Immutable fields that are part of the payload like _id, _rev or reported_date, ignore them.
It there is a parent in the payload object, check if it matches the original doc. If yes, do nothing.
If it does not match, check for the force_parent_update=true(name might change) query param, if it is not set, throw an error.
Intermediate steps like ensuring type is a valid contact_type, etc.
The basic algorithm is if some field matches the original doc, do nothing; else run the standard validations.
If some required field is missing from the payload, throw an error.
Finally, PUT the doc in DB.
I am a bit unsure about step 7, not having it is almost similar to having a PATCH request which might feel confusing for the user.
So the questions are:
Do we want the user to always include the required fields in the payload or do we populate them ourselves? Throwing an error if they are passed might be inconvenient in cases where the values are same, as there is no possibility of deleting those anyways.
Do we want to accept updated parent/contact as a string or dehydrated/hydrated lineage, or anything from these three options?
I think no fields should be auto-populated on PUT.
If we are talking about validation options here, this request should throw an error. That is … if we add lineage validation at all (which I’m not entirely sure if we should, at least for the moment),
If we are to talk validation, I think that the most basic validation would be to check that the lineage respects hierarchy settings (the contact types and how they are connected) and that the lineage tree is correct: the places in the lineage are directly linked and end with a root type place.
If we are talking about validation options here, this request should throw an error. That is … if we add lineage validation at all (which I’m not entirely sure if we should, at least for the moment),
If we are to talk validation, I think that the most basic validation would be to check that the lineage respects hierarchy settings (the contact types and how they are connected) and that the lineage tree is correct: the places in the lineage are directly linked and end with a root type place.
When updates like this are done, given that the hierarchy is correct according to the config, all the lineage of all the affected contacts need to be updated, right?
So, IIUC
If some doc called A gets an update on its parent/contact lineage, we would also have to update the lineage of all the docs that have A in their parent, contact lineage?
Great conversation here! Thanks everyone! Just want echo what Diana has already said with a few more design thoughts of my own:
PUT/PATCH
Stick with PUT in our initial apis. We can always come back later and add PATCH if it would be useful.
Lineage:
Do not allow updating the parent (or any of the other ancestor _ids).
Require that the parent value be provided, in the PUT call, but allow it to be either hydrated or dehydrated. If it is hydrated, then cht-datasource should dehydrate the lineage when saving.
This is just a convenience for allowing consumers to easily update contacts that they originally retrieved via the get-with-lineage apis.
Validate that the parent lineage matches what is in the existing doc in the DB (the one being updated). No other lineage validation is necessary. Just make sure it stays as it was originally.
Validate that the _rev provided on the PUT call matches what we see on the current doc in the DB (if the doc has been updated and has a different _rev we should just thrown an error and stop execution.)
@sugat and I thought that accepting the parent/contact _id in the form of a string for the contact/parent would be better and consistent with what we do for the create APIs. Better because we could avoid the hassle of validating the lineage.
Also, I am not sure why we need to validate lineage for a update call when we are anyways going to end up using the parent from the original doc.
My thought is we can accept the parent id as a string and match it against the original doc’s parent._id and throw an error if they do not match. That way we can also save the potential need to dehydrate as well.
Thinking a bit harder, I wonder whether we need this parent matching step at all?
IIUC, a doc having same _id and _rev as the one in Pouch should have the same content including lineage right?
So if the _rev and _id of the sent payload match, then the user did have the “latest” version of the Doc with them while making the call. My understanding is validating the lineage like you mentioned is probably to ensure this consistency i.e. the user is made aware that what they are trying to update is outdated in case the lineages of the payload and doc don’t add up. But I think that is taken care of by the _rev?
If parent field cannot be updated then, it should be ignored even if it is passed and not validated at all or better yet throw an error if it is passed rather than ignoring silently. Meaning that even if the end user passes something that is different than the value in the database, it should make no difference in the processing. It does not make sense that the value is required but cannot be updated.
So, for a PATCH api I would 100% agree. However, I think things are a bit more cloudy for a PUT api. Semantically, a PUT" replaces a representation of the target resource with the request content". The difference (in my brain) is that it is more of a “replace” action than an “update” action. So, the data we are using for the replace should be complete.
Semantics aside, my main motivation for requiring the parent lineage on the PUT is for consumer convenience.
If we just ignored any submitted parent values, that could be confusing to api consumers since it will not be immediately clear that any parent changes were not persisted. In general I think it is a bad idea to accept but ignore.
On the other hand, if we prohibit any parent value from being provided on the PUT, then we are effectively requiring any consuming code to take the extra step of removing the parent from the update data before submitting the PUT request. It seems safe to assume that anyone trying to update a contact/report has first retrieved that entity via the get or get-with-lineage apis. So, the entity data they are mutating will already contain the parent value. Then, once they have mutated the data so the entity is updated, they want to submit the update back to our PUT api. In that case it does not seem to make much sense that they would have to remove the parent…
Yes, this is precisely my thinking here. I agree that the _rev validation is most important because it proves the user is not working with stale data. The lineage validation is more of a benefit to the consumer. The server is always going to enforce that the lineage is not updated. The point of also validating the lineage provided by the consumer is to help maintain consistency between what is stored in the db and what the consumer thinks is stored in the db.
So, we should throw exceptions if the payload doesn’t line up with what is present in the DB like you mentioned in the reply to my comment?
That sounds good to me, because we can avoid confusion from the user’s perspective which might arise in case we just silently ignore immutable fields which are part of the payload, particularly in cases where some of them differ from what is present in the DB.
Where the author describes how to PATCH and practices to avoid
I think the idea we were going to implement with PATCH was somewhat of the style the author advises against:
So PATCH === “a sequence of operations to apply to a JSON document”.
This is great followup here @apoorvapendse and helps to clarify a lot of the questions I had! Sounds like it is time for a v2 of our update APIs…
(For the record, I still think our current approach is best for v1 as it is easier to integrate with the Couch flow, but I do like the idea of not having to retrieve the whole doc just to update a field or two…)