We previously helped build a just-in-time (JIT) solution to help prevent new duplicates from being created. Our focus has now shifted to fixing existing duplicates. Specifically, letting users decide what action to take (merge/delete/archive) on records flagged as potential duplicates, and adding an approval/audit step before those actions are finalized. Maybe these “actions”, that we’ll get into in a bit, could eventually be handled by the cht-conf tool [1][2]
While the JIT approach focussed on prevention, this next step is about correction. Currently, most of the automatic correction (merging, deleting, and archiving of duplicates) happens in our Databricks space. However, items with low confidence scores still require manual intervention. These records need to be flagged and sent back to the instance for review by users who have the right context to make informed decisions.
Building the prototype
To handle this, we’ve been experimenting with a prototype screen that lets users manage flagged duplicates directly. It borrows a few pieces from our WIP plugin PR [1][2][3]. The prototype is still rough, some parts are hardcoded to our context, but it’s functional enough to prove the concept.
It integrates with NgRx state and reacts to database document changes like other CHT screens. We’re also reusing the existing duplicate component (with a few small tweaks) to display the same configurable summary information seen in the JIT flow.
Updating the ddocs
To make the prototype work, we needed to adjust a couple of views that drive replication and querying. This is where we’d really appreciate some guidance.
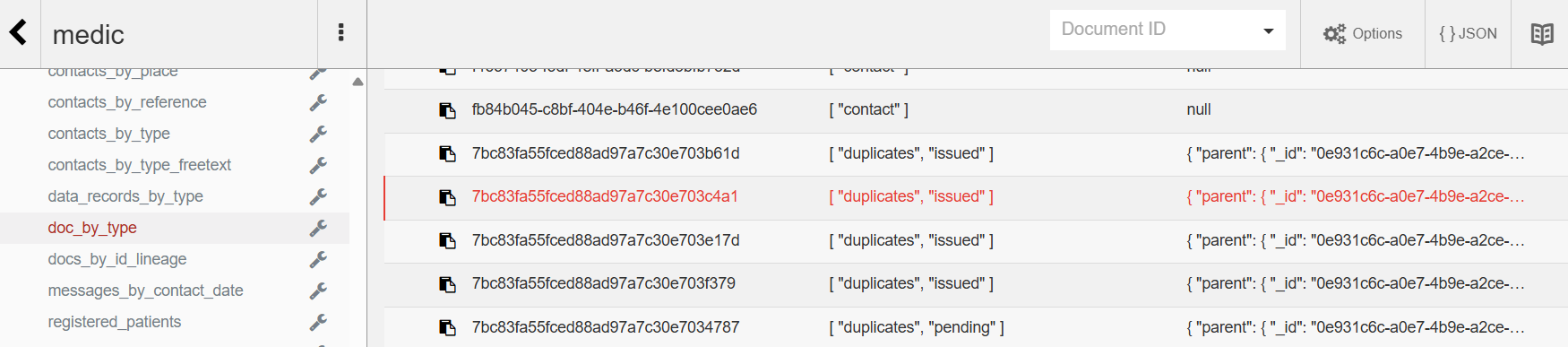
medic-client/views/doc_by_type:
By default, this view picked up our new document type (duplicates) automatically. However, to query the right docs for each user, we had to expose and additional state property (explained in more detail below). We also started emitting the parent as a value to ensure that offline users only replicate documents relevant to their specific scope.
medic/views/docs_by_replication_key:
Since CHT only allows for replication of certain document types, we added duplicates to the list.

We’ll get into the concerns a little later.
Extending the Authorization Service
To support these changes, we made a small change In the API space. In our app version (4.3.x) it was within the authorization service’s getAuthorizationContext method. We introduced an extra doc_by_type query that returns our duplicates documents that is then added to the subjects array for replication (since the original contacts_by_depth alone was insufficient for our needs).
While this works, it does introduce some extra sync delay, since we’re now making an additional query. This is method is hit quite often by offline users, so we’d like to optimize that - possibly by supporting replication by state or “depth”, so that users only pull down what’s actually relevant to them.
A snippet of the change:
const getDuplicateSubjects = (row, facilityId) => {
const subjects = [];
if(row.value){
current = row.value.parent;
while (current){
if(current._id === facilityId){
subjects.push(row.id);
break;
}
current = current.parent;
}
}
return subjects;
};
const getAuthorizationContext = (userCtx) => {
const authorizationCtx = getContextObject(userCtx);
return Promise.all([
db.medic.query('medic/contacts_by_depth', { keys: authorizationCtx.contactsByDepthKeys }),
db.medic.query('medic-client/doc_by_type', { startkey: ['duplicates'], endkey: ['duplicates', {}] })
]).then(([contactsByDepthResults, duplicatesResults]) => {
contactsByDepthResults.rows.forEach(row => {
const subjects = getContactSubjects(row);
authorizationCtx.subjectIds.push(...subjects);
if (usesReportDepth(authorizationCtx)) {
const subjectDepth = row.key[1];
subjects.forEach(subject => authorizationCtx.subjectsDepth[subject] = subjectDepth);
}
});
duplicatesResults.rows.forEach(row => {
const subjects = getDuplicateSubjects(row, authorizationCtx.userCtx.facility_id);
console.log('Duplicate subjects: ', subjects);
authorizationCtx.subjectIds.push(...subjects);
// TODO: replication depth
});
...
Document schema and structure
Each duplicates document defines a set of potentially duplicate contacts, along with the actions to take on each one. Here’s an example:
{
"_id": "7bc83fa55fced88ad97a7c30e703f379",
"_rev": "12-2107b24705b3ae899ff8de8124d1e784",
"type": "duplicates",
"name": "Test 10",
"contact_type": "dwelling",
"issue_date": 1759304952000,
"due_date": 1760428152000,
"priority": "high",
"state": "approved",
"comment": "Some comment here",
"items": {
"46b8a610-a011-487d-85f4-e460fd0de7f0": "canonical",
"0e931c6c-a0e7-4b9e-a2ce-ddb8c4033b64": "merge",
"fb84b045-c8bf-404e-b46f-4e100cee0ae6": "delete"
},
"parent": {
"_id": "0e931c6c-a0e7-4b9e-a2ce-ddb8c4033b64",
"parent": {
"_id": "f4657403-f5df-4eff-a5dc-befd3bfb732d",
"parent": {
"_id": "4d2f7817-ad7e-4f5e-8262-a41e860dbd15"
}
}
},
"meta": {
"created_by": "system",
"created_by_person_uuid": "",
"created_by_place_uuid": "",
"last_edited_by": "anro-chw-4125",
"last_edited_by_person_uuid": "3558df86-3844-4c7f-afe4-0703d8097198",
"last_edited_by_place_uuid": "0e931c6c-a0e7-4b9e-a2ce-ddb8c4033b64",
"last_edited_on": 1760717235855,
"audited_by": "admin",
"audited_by_person_uuid": "",
"audited_by_place_uuid": "",
"audited_on": 1760717284678
}
}
| Property | Value(s) | Purpose |
|---|---|---|
type |
duplicates |
Differentiates this doc from others |
name |
< string > | Title shown in the list |
contact_type |
< string > | Based on the contact types in the app config. Here, the value outlines the type of the contact IDs in this doc |
issue_date/due_date |
< ms timestamp > | Used for ordering and deadlines |
priority |
low, medium, high |
Controls list ordering (high = top) |
state |
issued, pending, approved |
Defines visibility and workflow stage |
comment |
< string > | Optional feedback or audit notes |
items |
{id: action} |
Maps each duplicate contact to its action (canonical, merge, delete, archive) |
parent |
< object > | Mirrors CHT’s parent structure, used for replication |
meta |
< object > | Standard metadata fields for audit trail |
Considering custom views
One concern, as mentioned in the ddoc section, is the maintainabillity of modifying the ddocs. Since CHT warns that core design docs may be overwritten during upgrades, it might be safer to use custom indexes/views. Functionality we helped introduce a while back via the cht-conf tool.
That said, I’m a little hesitant to rely on a custom view in such a core part of the app. Off the top of my head, to facilitate something like that we’d need to:
- query whether additional view(s) are available on the
medicdb - maintain a dynamic list of views and their params, whose results should be included as replication subjects. Depending on the complexity, the contents might need to be parsed as js. For example, in our context, CHWs should only replicate docs with a
stateof “issued”.
Since offline users hit this often, it could be an issue if not done optimally. Still, for CHT to support diverse plugins this might be the right direction to explore. Maybe I’m overthinking it, but I’d be interested to hear if anyone has approached this differently.
Current output
The prototype represents a first step toward giving users direct control over managing duplicate data. It’s still very rough and un-styled but seems to work.
Introduced an additional nav “Duplicate” button:
![]()
To maintain consistency with rest of CHT, items for selection are displayed on the left-hand-side and “content” is displayed on the right. The content is also displayed in cards to mirror contact “profile” screens. The big difference being that the editing of the doc takes place right in the content pane.
As a CHW:
A list of “issued” docs will be displayed to the user. As explained above, each item contains a collection of record IDs, of the same type, that have been flagged as duplicates. After pressing the “edit” button, additional controls appear next to the “open” button. Selecting an item as “canonical” displays an “action” dropdown on the remaining items. After the user submits the changes, the state moves to “pending” , and the record will be removed from view.


As an auditor (admin):
A list of “pending” docs will be displayed to the auditor. After pressing the “edit” button, the user is able to view the selections made by the CHW. Based on the state of the doc, the auditor can decide to Reject or Approve it. A comment should be entered when rejecting a doc to guide the CHW making the correct capture.Once the state changes the record is removed from view.


We’d really appreciate any thoughts or advice.
- Is there a better long-term approach?
- Any suggestions for optimizing replication to avoid added sync delays? While still allowing for extending functionality.
- Thoughts on the schema or flow, anything we might be missing?
