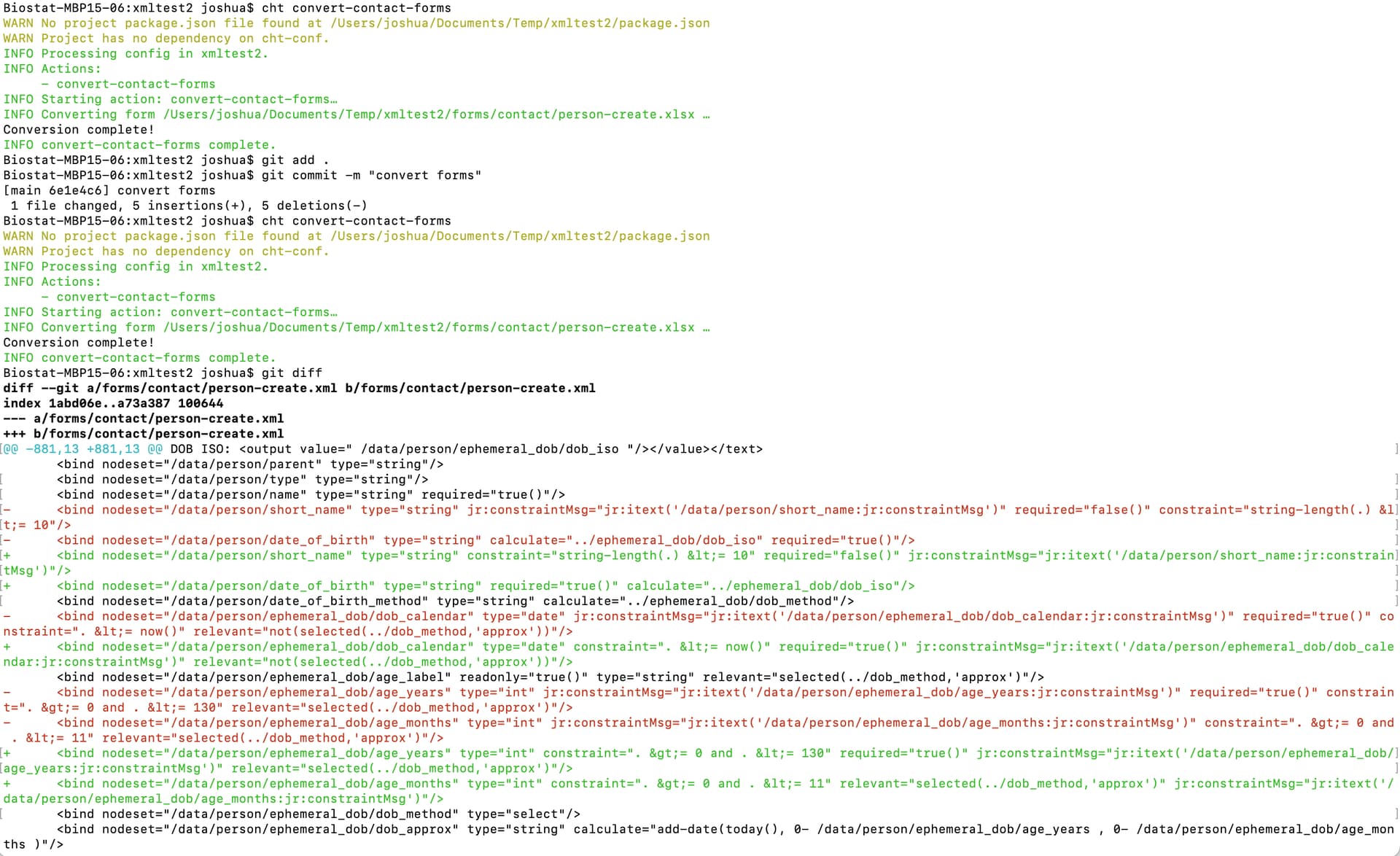
An issue that I’m having is that cht convert-contact-forms changes the .xml output even when the source .xlsx file does not change. This is a problem for version control because it makes it difficult to see which forms have changed.
Yes, sadly our current version of pyxform does not deterministically sort the xml attributes. So, regenerating the xml results in a randomized sorting that can be different each time the form is converted (which as you have noted is a huge pain for version control).
The “good” news is that this has been fixed in the upstream version of pyxform, and an issue has been logged to pull these changes into medic/pyxform!
Unfortunately I do not have any specific timeline, but I can say that there is nothing blocking that issue from being addressed. It is just a matter of an alignment of dev time/priorities (or someone submitting a PR) …
In case others are having this issue, here is some code I wrote (with ChatGPT ) that will sort the xml files. This could be used as part of a Git pre-commit hook.
My code isn’t great - the processed xml files don’t run work correctly (they fail validation with cht-conf because of namespace issues). But the processed xml files are useful for version control.
import xml.etree.ElementTree as ET
import glob
import re
from xml.dom.minidom import parseString
def pretty_print_xml(xml_string):
dom = parseString(xml_string)
pretty_xml = dom.toprettyxml(indent=" ")
# Remove unnecessary blank lines
pretty_xml = '\n'.join([line for line in pretty_xml.split('\n') if line.strip()])
return pretty_xml
def sort_attributes(element):
if element.attrib:
element.attrib = {k: element.attrib[k] for k in sorted(element.attrib)}
def sort_elements(element):
sort_attributes(element)
element[:] = sorted(element, key=lambda child: (child.tag, child.text if child.text else ''))
for child in element:
sort_elements(child)
def sort_xml(xml_string):
parser = ET.XMLParser(target=ET.TreeBuilder(insert_comments=True))
root = ET.fromstring(xml_string, parser=parser)
sort_elements(root)
return ET.tostring(root, encoding="utf-8", method="xml").decode("utf-8")
def normalize_whitespace(xml_string):
# Normalize whitespaces between tags
xml_string = re.sub(r'>\s+<', '><', xml_string)
# Remove spaces around = in attributes
xml_string = re.sub(r'\s+=\s+', '=', xml_string)
return xml_string
def sort_and_overwrite_xml_files(directory):
for xml_file in glob.glob(f"{directory}/**/*.xml", recursive=True):
with open(xml_file, "r") as file:
xml_content = file.read()
sorted_xml = sort_xml(xml_content)
normalized_xml = normalize_whitespace(sorted_xml)
beautified_xml = pretty_print_xml(normalized_xml)
with open(xml_file, "w") as file:
file.write(beautified_xml)
sort_and_overwrite_xml_files("forms")
I am experiencing the same version control frustration when forms aren’t changing, and was looking to see if anyone had a workaround before reporting, and came across this post.
Finding a solution to this would be extremely very helpful to avoid the silent introduction of bugs or changes to forms. It’s otherwise easy to have unintended form changes being committed by any one of the config contributors.
Does anyone have a suitable workaround already, or is anyone in the community already considering picking this up? Is there an open issue somewhere for this to be tracked?