We recently upgraded to CHT v3.13 in Uganda Region 1 which covers about 1925 VHT Members distributed across 6 branches. It was however noted that, for users with poor network/slow internet, the application stops working.
These are users who have already logged in and synced their data, so the expectation is the application will work in the offline mode while the network is poor. This has been observed for approx 35 VHT Members in different branches.
Hello @derick. We are currently trying to see how we can have the UG team get the logs from the devices. They have not noted the issue when logging in from the browser yet.
Is there a simple way you can suggest which will enable them to fetch these logs from their devices?
Thank you @diana
I have shared the instructions on fetching the logs with our UG team. I will share them with you as soon as I get them.
For the follow up questions:
No, no pages are loading. Only the spinner is visible
The devices start working once the VHT members return the phones back to HQ where the internet connection is good. But as soon as they head back, and lose connectivity, the issue re-emerges
I tried replicating your issue locally, on 3.13, simulating a very slow network, and I’m not seeing the infinite spinners in contacts. The long loading spinner occurs before the actual page is loaded, just like the issue above describes.
The issue I linked above has instructions about how to throttle network in Chrome desktop browser. Can you try to follow them, while being logged in with one of the users experiencing the loading issue and see if you can replicate it?
Hello @antony and @diana
The QA team has not been able to replicate the issue on their end. We are still following up with the stakeholders to try and simulate the conditions that lead to the issues, after which we shall be able to share the logs.
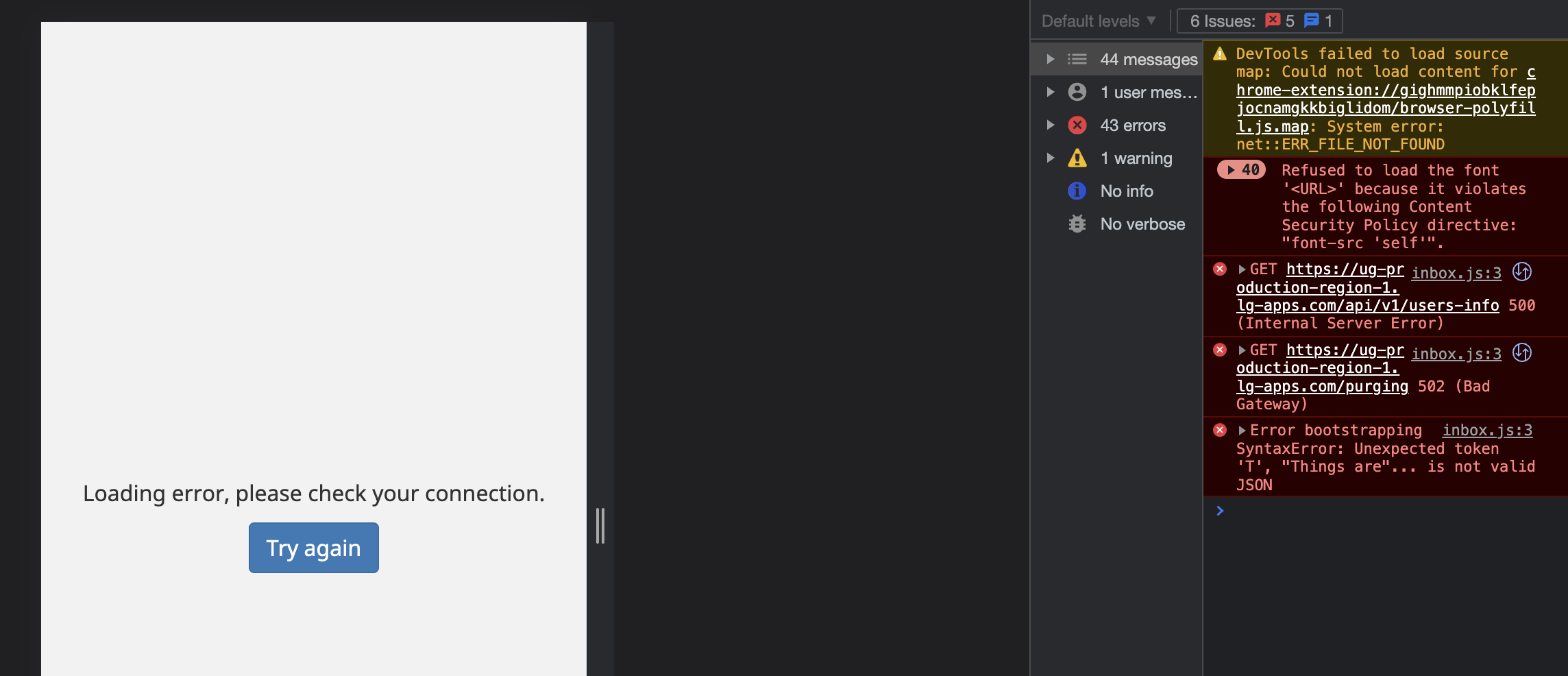
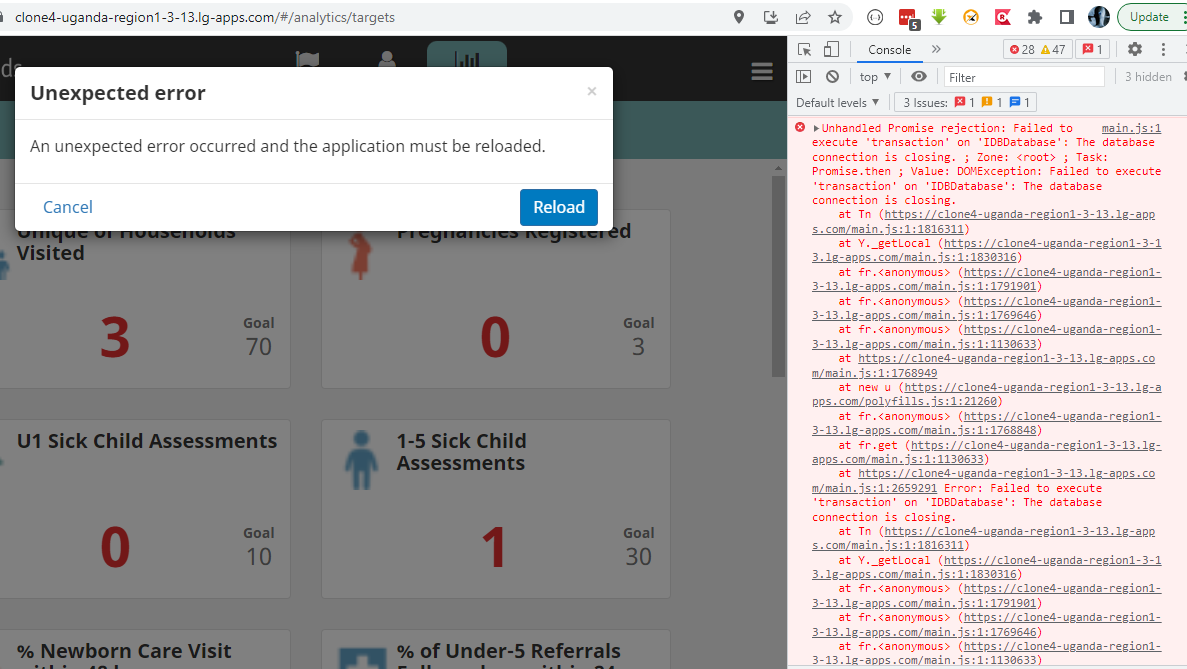
I have also not able to replicate the issue above on my end, as per the suggestions shared above. This is because, when I try to log in to production with a user they shared (internet is okay and I am able to log in the user in a dev instances), I get this error instead:
I see a bunch of errors there, the first one seems to be caused by a browser extension. Could you please use a clean browser when trying to connect?
The second errors are server errors, further investigations should start with checking API logs on the server and seeing the source of the crashes.
I have also not able to replicate the issue above on my end, as per the suggestions shared.
When I login a fresh, the behavior changes and operation stabilizes for those reported with error fetching tasks, this is the same work around that is being used in the field to get relief, but not feasible for the large numbers.
I have 2 accounts that have been logged in for 2 weeks now, and tried observing with throttled connections, but still this doesn’t seem to reproduce the offline issue.
Stakeholders (@Moses_Obulei@Aguti_Sandra ) have been able to share some Logs from the field occurrences of this issue.
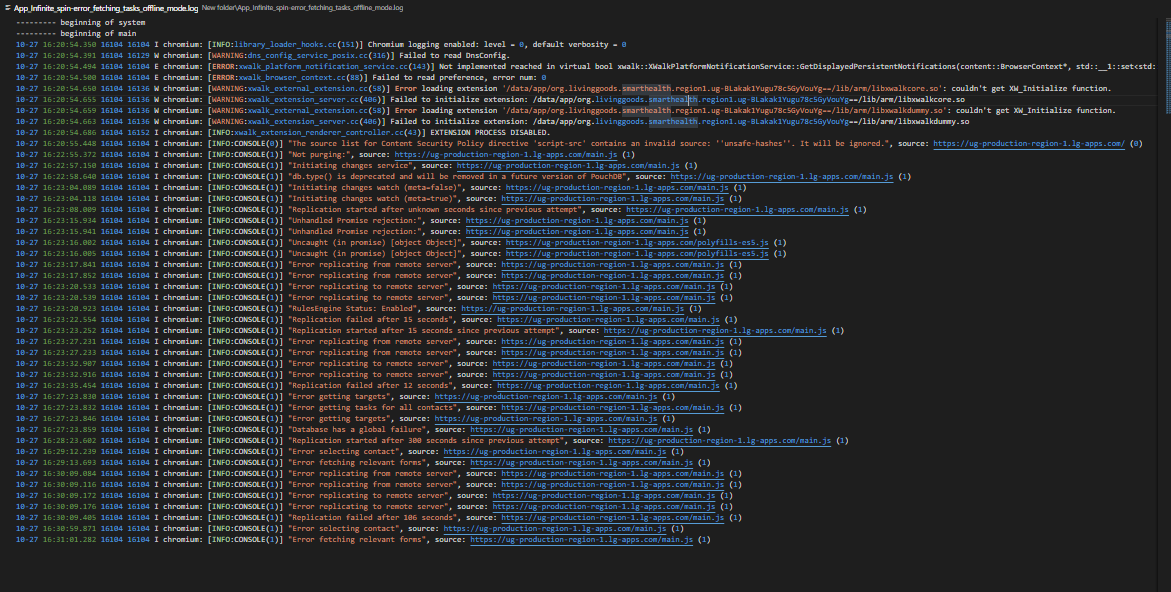
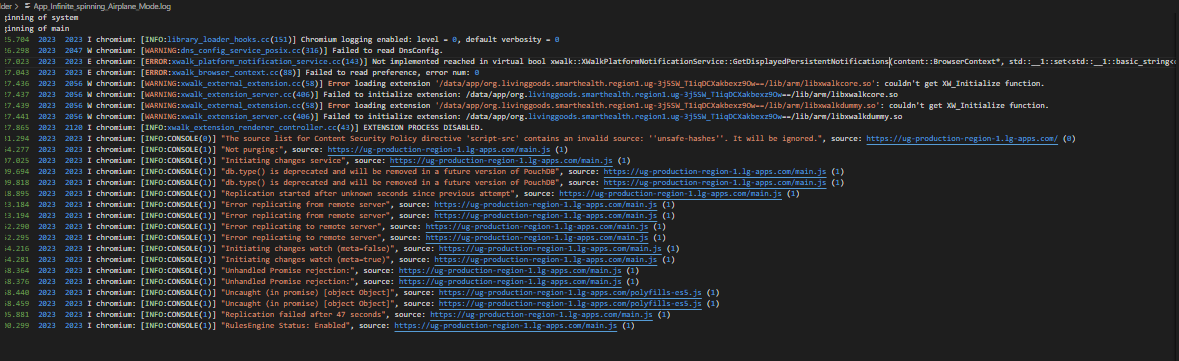
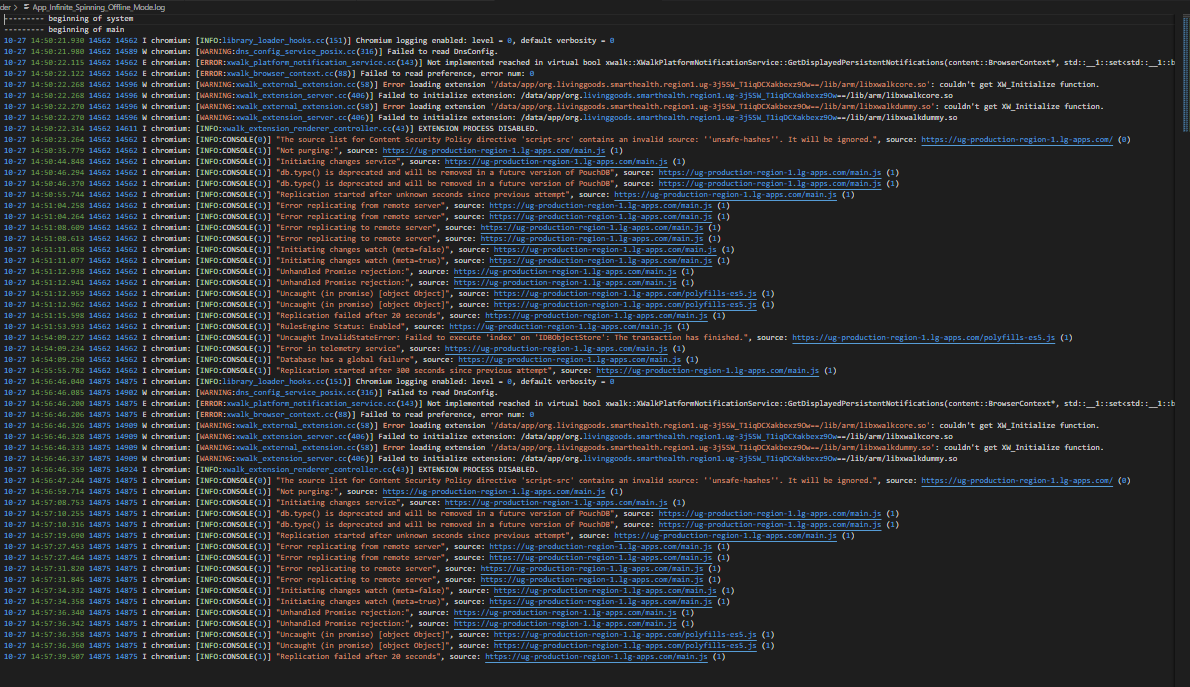
Some of the Logs shared from different scenarios with some affected users from the field
It looks like PouchDb is erroring out. This error is visible in the first and third images that you shared: Database has a global failure..
The specific cause for this error is very hard to pin down. In one instance, it was caused by large attachments (Database errors on some devices when forms have large attachments · Issue #6699 · medic/cht-core · GitHub), in others by some PouchDb internal cleanup (compaction), in others because the devices ran out of storage.
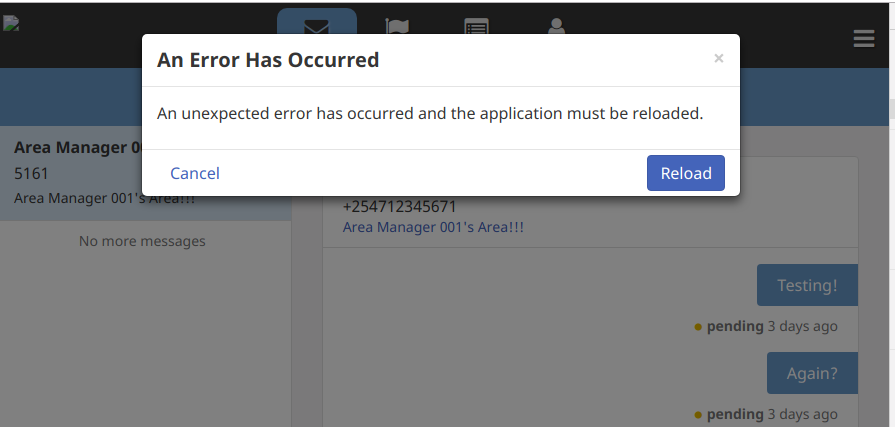
The modal can be cancelled, and it does not force a reload (reloading will not necessarily resolve the problem).
Have your affected users seen this modal? If not, I’ll submit an issue to check which PouchDb errors are not caught. To be completely clear, the modal does not have any functionality besides warning the user that something has gone wrong, as opposed to infinite spinners and no information.
We are experiencing a similar Modal, It could be related to the one you have above.
But this usually comes when the the app has been offline and one tries to access it when online.
The modal text can be changed with translations, so given the similarities, I think it’s safe to assume you’re also encountering PouchDb errors.
Coming online will trigger replication, which will involve reads and writes from the local PouchDb database. I suggest you check browser logs to see if you can get more insight into what is happening.
Have a look at these browser logs that we have managed to replicate from the Modal text.
hope the errors generated are able to give more insight to further the investigation on the issue.
the crash happens in Chrome desktop (is this correct?) - Yes that is chrome desktop
does reloading the app resolve the issue? On the browser- yes this is resolved
On the CHT app - No Reloading the app doesnot fix this
does this happen only when loading targets or does it happen on any tab? (fe: navigate to the tab and reload on that tab). This can happen when one attempts to load any tab
does throttling the internet connection to offline (from browser network settings tab) and reloading change the behavior. Throttling internet connection and reloading the app does change the behaviour on the browser but not on the CHT app.
can you please share the whole browser log, from the reload up until the crash? (As of now, i havenot yet succeeded in replicating this crash again from the browser)
does this happen for a few select users or is it a common occurrence for all users? Yeah this is a common occurence, initially few users were affected but the number has kept growing.
Please keep us updated on the developments.
It would be most helpful if you could find one user that you can consistently replicate this for, and if possible collect all browser logs and share them, also making note of every action that you make from the point you log in until you see the error triggered.