So, the document is being posted to the database. I am trying with just one document of a new person and pushing it to medic/_bulk_docs. The dummy payload looks like this (output from the allDocs) : '{"docs":[{ "id": "fafcc765-449b-42c8-9990-5a9245b78546", "key": "fafcc765-449b-42c8-9990-5a9245b78546", "value": { "rev": "1-884fb399a0175e97f638852f59a5ff3d" }, "doc": { "parent": { "_id": "7115fafe-c42b-4d62-9c96-a70525b13fd4", "parent": { "_id": "2d6a9b56-8e05-4db3-87f7-0a7bc0a86418" } }, "type": "person", "name": "offline_person_7", "short_name": "", "date_of_birth": "2020-06-07", "date_of_birth_method": "", "ephemeral_dob": { "dob_calendar": "2020-06-07", "dob_method": "", "ephemeral_months": "6", "ephemeral_years": "2022", "dob_approx": "2022-06-07", "dob_raw": "2020-06-07", "dob_iso": "2020-06-07" }, "sex": "male", "phone": "", "phone_alternate": "", "role": "patient", "external_id": "", "notes": "", "meta": { "created_by": "afgoye_hfo", "created_by_person_uuid": "197fd687-fc43-4842-8794-cf9ac8300a16", "created_by_place_uuid": "7115fafe-c42b-4d62-9c96-a70525b13fd4" }, "reported_date": 1654597913219, "_id": "fafcc765-449b-42c8-9990-5a9245b78546", "_rev": "1-884fb399a0175e97f638852f59a5ff3d" } }], "all_or_nothing": true}'
The payload normally has a lot of documents (that already exist) in this array but right now i am just trying to push the new one. All_or_nothing seems to have been deprecated, so question one is, how to deal with conflicts? I was hoping that with the same id, there would be some option to not upload them or to merge them (since at that point we don’t know which document is new relative to the server). And question two is: The document is being pushed to the DB and I can see it with the ID provided, however it is not shown in the UI. Is the document expected to be in a different format so that it can be read and shown to the user?
Edit 1 : So, the problem is that the documents are being provided with _id and _rev since they exist in the initial DB, but the new ones don’t exist in the db to be uploaded to. So when uploading, it will throw a Conflict, can’t update the document and it won’t be loaded. The issue now is to find out which documents don’t exist in this 2nd db that were created in the 1st one, and remove the _id and _rev so that one is provided by the db. I thought that if you provide _id and _rev one doc would be created if it doesn’t exist with that same id and rev but appears not to be the case
I wonder if, instead of just trying to push the docs into the existing DB via _bulk_docs, maybe it would be easier to create a new PouchDB with the provided docs and then replicate that DB back into the medic DB? Once again, I have not tried this, but it feels like the complexities you are running into here are precisely what the Pouch replication logic is supposed to handle.
It sounds like it should be fine to replicate between to separate Pouch instances, so maybe you can create an ad-hoc PouchDB with the data you want to import and then just replicate that data back into the existing medic PouchDB on the device.
Thanks for your feedback, it might indeed make sense. I have been trying your idea, but although I am getting an OK from the server the new resource is still not being created. Is it because the new Doc has an _id and _rev but there is not an instance of that _id in the server db?
From the docs I was under the impression that this is done like this but seems to not be working for some reason
Edit 1 : I feel like when I create a new local DB with the provided docs, it creates a new ID and REV despite me having new_edits=false and providing _rev and _id.
After doing some more reading on this, I don’t see any way that Couch/Pouch would let you create a new doc with a custom _rev value. It seems like that always must be generated by the DB itself. (Should be able to provide a custom _id value for the new docs without issue, unless there is an existing doc in the DB already using that _id.)
So, I think it comes down to how you want to handle docs that exist both on the server and in the import data.
If you don’t care to import any data for those existing docs (and you just want the new docs) then something like this might work:
Delete the _rev field from the docs being imported (probably can do this as part of the export process).
Push the data to the medic database via the bulkDocs endpoint
a. New docs should be added successfully
b. Any docs with conflicting _id values will fail to be added with 409
If you want to import the data for the existing docs too and you want to prefer the imported data for these docs over the data already on the server, something like this might work:
Delete the _rev field from the docs being imported
Get all the _id values of the docs being imported and lookup the actual _rev values for the existing docs in the medic db using the allDocs call.
Set these correct _rev values onto the existing docs you are importing
Push the data to the medic database via the bulkDocs endpoint
a. New docs should be added successfully
b. All changes for existing docs should be accepted since you are using the proper _rev values.
If you want to import the data for the existing docs, but instead of just preferring the imported data, you want to throw yourself on the mercy of CouchDB’s conflict resolution logic something like this might work:
Delete the _rev field from the docs being imported
Use bulkDocs to load the data into a temp DB.
Replicate the temp db to medic
a. New docs should be added successfully
b. For existing docs, the _rev values will not match. Still, they should technically replicate successfully, but it will trigger a new conflict for the doc. The next time someone tries to read that doc, Couch will deterministically select one of the conflicts to return…
Thanks for the detailed answer. What I am looking for is the first option (it will be mostly used to collect new data on new patients and then pushed), and it does indeed upload to the database when I push it to the medic database using that endpoint, the issue is that somehow it is not updated in the GUI. So I am doing a POST request to the bulkdocs with include_docs = true and attachments = true, and I get the _id in the response (which I am able to see in the database when I access _utils) BUT I cannot see the new created contact when I search for him in the contacts tab.
Edit 1 : So it seems that it works if we unwrap the “doc”: {} part (additional to the steps you mentioned) and leve the content (at least to upload patients) like this I can see the created patient in the UI when trying with one document. Now trying with a bunch of docs exported from the DB, there is the issue that it seems to be returning as soon as there is a conflict. And as there are alot of documents with conflicts (since they already exist) it doesn’t get very far the to be create aren’t considered.
I am assuming this, because if I am not mistaken I should be getting a response _id for every entry right? So some would come with a conflict and others with “created” or something like that. However the whole response is :
Edit 2 : Seems like I was having a problem with my regex to delete the _id because of the translations files in the payload (which also have _id in them apparently). Will fix this and let you know how it goes
if I am not mistaken I should be getting a response _id for every entry right? So some would come with a conflict and others with “created” or something like that.
Right, that is my understanding of how the bulkDocs endpoint should behave (at least according to the documentation). It should process all the docs in the request and not stop even if it finds a conflict.
my regex to delete the _id
Wait, why are you deleting the _id (did you mean _rev)? I would think that you would need to keep the _id so that you know which docs are actually existing ones…
So, I am deleting _rev right before exporting the data as well as unwrapping “doc” in the object and seems to be working now + I can see it in the UI, thanks so much for this back and forth! I would like to do a pull request with this, do you think it is of interest? I would like to add additional features like disabling the buttons according to roles + changing the name of the downloaded data file to be more precise (maybe name of facility the person is entitled or username) but I think it should be a decent version right now.
EDIT 1: So I am trying to use your suggestion for the download of data to upload data offline (grabbing Pouchdb of the user) and then letting it sync whenever online, however I am getting a replication denied. Any idea why this would be the case? (The changes are showing locally though, after logging in to offline user → create patient → logging off → logging in to different user → going offline → uploading to PouchDB )
Hmm I have an idea of what might be going on here. I have recently been studying more about the actual replication process that the webapp uses to sync between PouchDB and CouchDB. One big thing to note is that the api server is responsible for proxying communication between Pouch and Couch, and one of the things it does is filter request data from offline users so that offline users cannot replicate docs that they do not have access to…
This could cause issues if the user trying to perform the replication does not actually have access to the new data. (In the case of new contacts, they would need to share the same contact tree as the user.
Thanks for digging this, it helped me get to a next step. I created a supervisor of a branch, above the CHW that is taking care of a household. When creating a patient with this CHW in this household > downloading the data offline > logging as the supervisor > uploading data offline > going online > this will correctly update the server. However if some assessment was done while offline, in the server I will have the new contect but not the attached report, even though locally I have it.
EDIT 1 : Surprisingly enough the death form IS correctly displayed in the server after pushing contact + death report offline, however the form doesn’t show when I push contact + custom form ( in this case I only see the contact)
EDIT 2: I have the feeling that it has to something to do with transitions. Seems like death reporting is supported out of the box with value “true”, and I feel like accept_patient_reports might have something to do with it. I have set it to true but seems to not be enough
EDIT 3 : Could is also be possible that we need to specify the permission? Seems to be defaulting to all permitted if left blank but perhaps it’s not the case? I would like to test this but I am not sure what kind of permission keys are allowed, do you know where can_register_pregnancies comes from?
EDIT 4: Going back to the online API call to the /medic database, as an admin I see the form + contact created. However for the CHW and CHW supervisor I only see the contact created, so seems like it’s just like what was happening offline. This makes me think that it really might be something with configuration. Is there somewhere I can specify this form to be available to others? make it public maybe?
EDIT 5 : Creating an ad hoc db for the files and importing with replicate.to as you previously mentioned is working with an online profile (offline profiles seem to not have access to this endpoint). One thing is that reports are only showing for online profiles, for offline profiles it is only showing the contact as previously mentioned. I guess offline should work too with the integrated sync from CHT since instead of using an ad hoc db, I am using the user db window.PouchDB(‘medic-user-username’) so in a way it’s the exact same thing, assuming “sync now” is taking the users db and calling a replicate.to on it. The problem seems to be that although the reports are there, they seem to be ignored somehow by offline profiles. Is there a file where offline / online restrictions are defined? If I could allow offline users to see all forms I think everything would be fixed
Hmm, can you see the reports that were submitted by the CHW when logged in as the supervisor? I would think (perhaps naively) that if the user could see the reports, they would be able to replicate them back to the server…
That being said, I think there are a few things that might affect whether the supervisor can see/replicate reports.
Before anything else, it is worth confirming that your supervisor’s role does not have a specific replication_depth configured. I am pretty sure if there is no config, than the default is to replicate everything below (above?) the user in the tree.
As you mentioned, it also might be a permissions issue. It is worth verifying that your supervisor role has at least the following permissions (and maybe any others that sound relevant):
Sorry for the late response. I had tested with replication depth, I also thought by default you should have access to all if nothing is specified but even specifying max depth didn’t help. I tried permissions too but I will try it again maybe even combine everything and let you know
@delcroip and @magp18 - hello! I’m reviving this old thread to see if you have any updates that you’d like to share with the community?
Specifically, I believe you were able to get some level of peer to peer functionality working in production, is that correct? It would be really great to get a write up of how well this is working, what scale you’re operating at (number of devices, how often they p2p sync, aprox. how many records are synced and exist in total etc) and any issues you’ve faced.
Finally, it would be extra great if there is any public code you could share so it might be possible for others to follow in your footsteps.
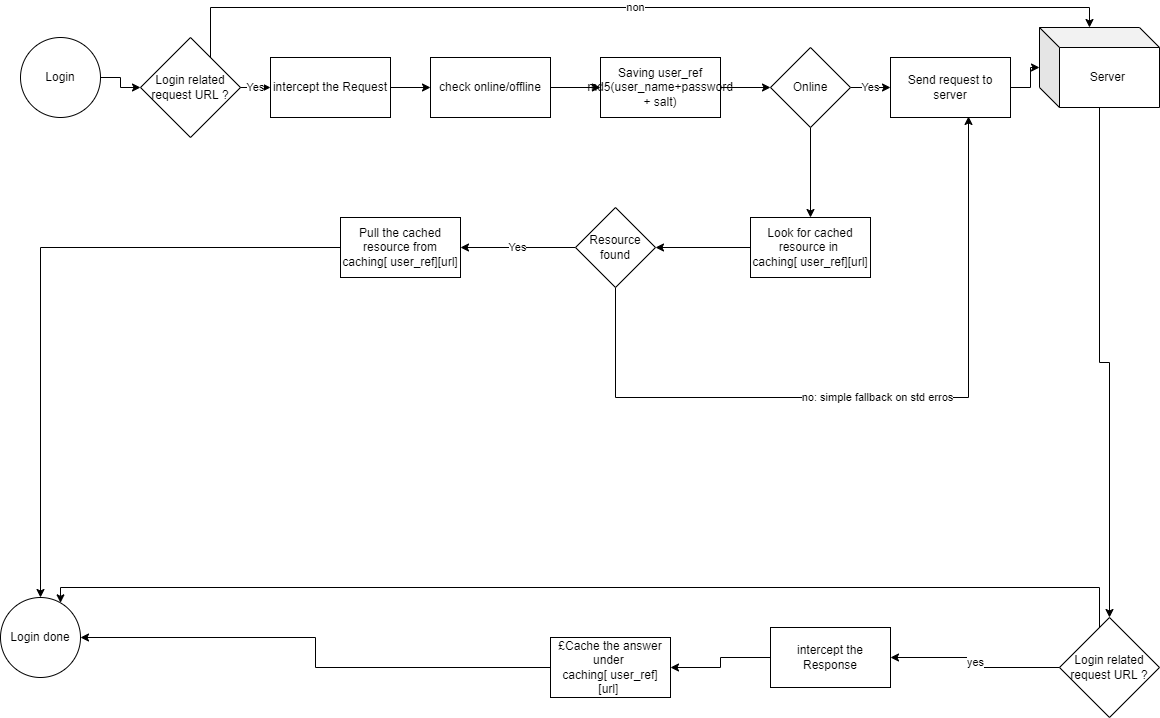
What we did: Added a download and upload button to the screen.
Then you could download the database to a file. This file could then be sent via bluetooth to a peer and uploaded by the same to the database and synchronized to the server. There are a lot of improvement steps as @gareth mentioned but unfortunately we didn’t have more time under that mandate.
If we get time to get back to it, will definitely let you know !